Identifying sample swaps
9/18/2020
library("pheatmap")
library("tidyr")
library("jaffelab")
library("here")
library("VariantAnnotation")
library("SummarizedExperiment")
library("devtools")
library("BiocStyle")In order to resolve the swaps to our best ability we need four data sets. Here we have load snpGeno_example which is from our TOPMed imputed genotype data, a phenotype data sheet (pd_example), a VCF file of the relevant SPEAQeasy output (SPEAQeasy), and our current genotype sample sheet (brain_sentrix). This file is wrote in the directory listed below.
load(here("sample_selection", "snpsGeno_example.RData"), verbose = TRUE)## Loading objects:
## snpsGeno_exampleload(here("sample_selection", "pd_example.Rdata"), verbose = TRUE)## Loading objects:
## pd_exampleSpeaqeasy <-
readVcf(here(
"pipeline_outputs",
"merged_variants",
"mergedVariants.vcf.gz"
),
genome = "hg38"
)
brain_sentrix <- read.csv(here("brain_sentrix_speaqeasy.csv"))We can see that the genotype is represented in the form of 0s,1s, and 2s. The rare 2s are a result of multiallelic snps and we will drop those. 0 represent the reference allele with ones representing the alternate. We can see the distribution below.
Geno_speaqeasy <- geno(Speaqeasy)$GT
table(Geno_speaqeasy)## Geno_speaqeasy
## ./. 0/1 0/2 1/1 2/2
## 14096 7803 4 6018 9Given this we convert we convert the Genotype data from SPEAQeasy to numeric data. The “./.” were values that could not accurately be determined and are replaced with NA.
colnames_speaqeasy <- as.data.frame(colnames(Geno_speaqeasy))
colnames(colnames_speaqeasy) <- c("a")
samples <-
separate(colnames_speaqeasy,
a,
into = c("a", "b", "c"),
sep = "_"
)## Warning: Expected 3 pieces. Additional pieces discarded in 42 rows [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15,
## 16, 17, 18, 19, 20, ...].samples <- paste0(samples$a, "_", samples$b)
samples <- as.data.frame(samples)
colnames(Geno_speaqeasy) <- samples$samples
Geno_speaqeasy[Geno_speaqeasy == "./."] <- NA
Geno_speaqeasy[Geno_speaqeasy == "0/0"] <- 0
Geno_speaqeasy[Geno_speaqeasy == "0/1"] <- 1
Geno_speaqeasy[Geno_speaqeasy == "1/1"] <- 2
class(Geno_speaqeasy) <- "numeric"## Warning in class(Geno_speaqeasy) <- "numeric": NAs introduced by coercioncorner(Geno_speaqeasy)## R14030_H7K5NBBXX R14184_H7K5NBBXX R13904_H7K5NBBXX R14296_H7JLCBBXX R14247_HF3JYBBXX R15093_HFY2MBBXX
## chr1:4712657_G/A 2 1 2 1 1 2
## chr1:7853370_G/A NA NA NA NA NA NA
## chr1:9263851_G/A NA NA 1 1 1 NA
## chr1:13475857_T/C NA NA NA NA NA NA
## chr1:15289643_G/A NA NA NA NA NA NA
## chr1:15341780_G/A NA NA NA NA NA 1We then make a correlation matrix to find the possible mismatches between samples.
speaqeasy_Cor <- cor(Geno_speaqeasy, use = "pairwise.comp")
corner(speaqeasy_Cor)## R14030_H7K5NBBXX R14184_H7K5NBBXX R13904_H7K5NBBXX R14296_H7JLCBBXX R14247_HF3JYBBXX R15093_HFY2MBBXX
## R14030_H7K5NBBXX 1.00000000 0.13507812 0.01657484 0.03106472 0.03384912 0.18938568
## R14184_H7K5NBBXX 0.13507812 1.00000000 0.09347004 0.18748043 0.07080491 0.04720309
## R13904_H7K5NBBXX 0.01657484 0.09347004 1.00000000 0.04958385 0.28798955 0.25477682
## R14296_H7JLCBBXX 0.03106472 0.18748043 0.04958385 1.00000000 0.16653808 0.27251010
## R14247_HF3JYBBXX 0.03384912 0.07080491 0.28798955 0.16653808 1.00000000 0.14097339
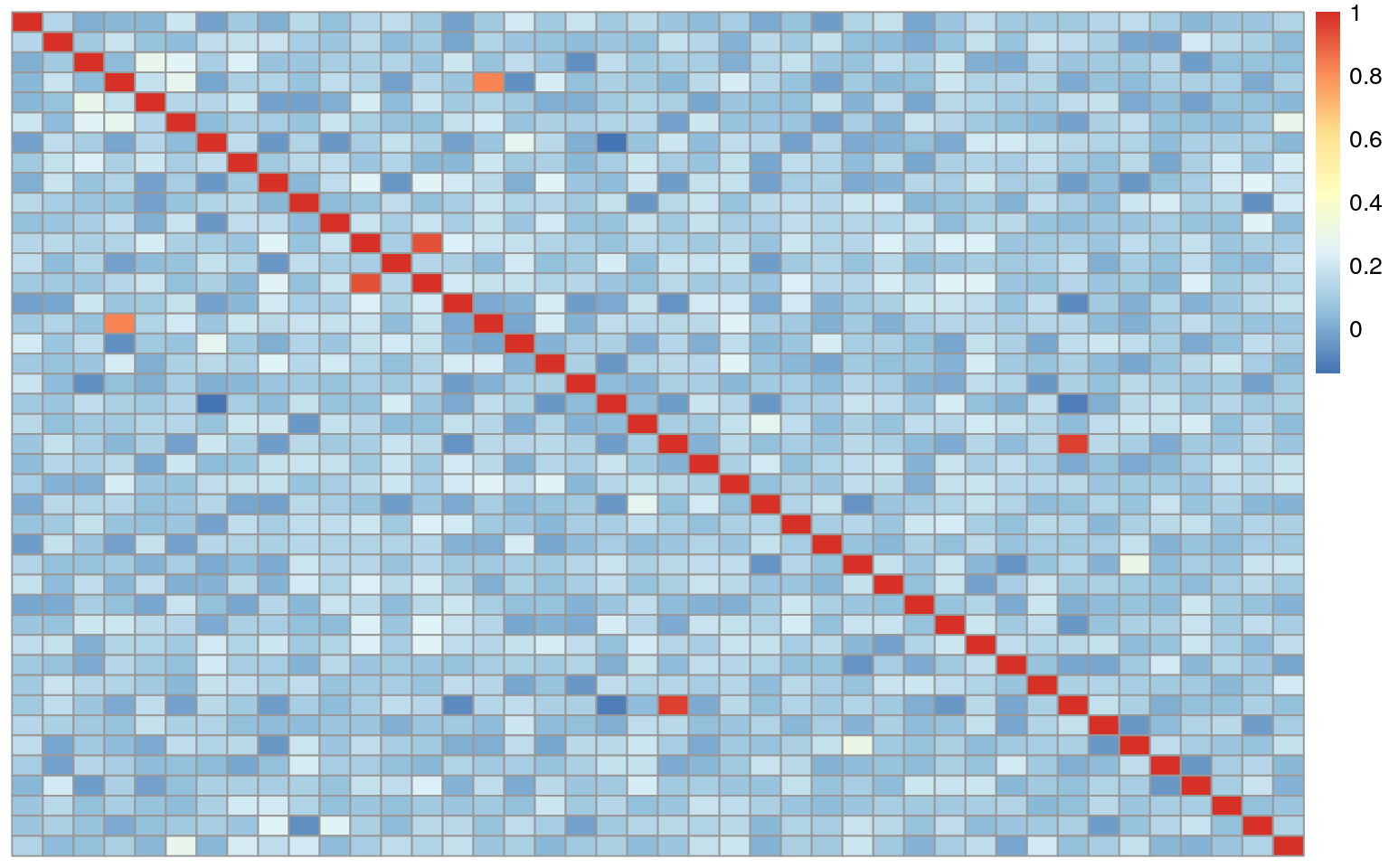
## R15093_HFY2MBBXX 0.18938568 0.04720309 0.25477682 0.27251010 0.14097339 1.00000000Here in the heatmap below we can see that several points do not correlate with themselves in a symmetrical matrix. This could be mismatches, but it also could be a result of a brain being sequenced twice. We will dig more into this later on.
We repeat the process for the genotype data from TOPMed. First creating our numeric data for the genotypes.
## Geno_example
## 0|0 0|1 1|0 1|1
## 9656 6956 7185 7535## 4463344375_R01C01 4463344375_R01C02 4572348848_R01C02 4572348855_R01C02 5535549043_R01C01
## 4463344375_R01C01 1.00000000 0.21736687 0.17615291 0.16590842 0.05367081
## 4463344375_R01C02 0.21736687 1.00000000 0.13803954 0.14670605 0.07697879
## 4572348848_R01C02 0.17615291 0.13803954 1.00000000 0.10600440 0.09356496
## 4572348855_R01C02 0.16590842 0.14670605 0.10600440 1.00000000 0.04874508
## 5535549043_R01C01 0.05367081 0.07697879 0.09356496 0.04874508 1.00000000
## 5535506145_R01C01 0.21189898 0.18114194 0.17829111 0.08186958 0.05331113
## 5535506145_R01C01
## 4463344375_R01C01 0.21189898
## 4463344375_R01C02 0.18114194
## 4572348848_R01C02 0.17829111
## 4572348855_R01C02 0.08186958
## 5535549043_R01C01 0.05331113
## 5535506145_R01C01 1.00000000In this case the data only appears to have samples that match themselves. However there is the potential for a second kind of error where a brain has two samples, however the do not match each other.

In order to dig into this further we will collapse the correlation matrices into a data table shown below.
corLong <-
data.frame(cor = signif(as.numeric(correlation_genotype), 3))
corLong$rowSample <-
rep(colnames(snpsGeno_example), times = ncol(snpsGeno_example))
corLong$colSample <-
rep(colnames(snpsGeno_example), each = ncol(snpsGeno_example))
corLong <- corLong[!is.na(corLong$cor), ]
head(corLong)## cor rowSample colSample
## 1 1.0000 4463344375_R01C01 4463344375_R01C01
## 2 0.2170 4463344375_R01C02 4463344375_R01C01
## 3 0.1760 4572348848_R01C02 4463344375_R01C01
## 4 0.1660 4572348855_R01C02 4463344375_R01C01
## 5 0.0537 5535549043_R01C01 4463344375_R01C01
## 6 0.2120 5535506145_R01C01 4463344375_R01C01corLong2 <- data.frame(cor = signif(as.numeric(speaqeasy_Cor), 3))
corLong2$rowSample <-
rep(colnames(Geno_speaqeasy), times = ncol(Geno_speaqeasy))
corLong2$colSample <-
rep(colnames(Geno_speaqeasy), each = ncol(Geno_speaqeasy))
corLong2 <- corLong2[!is.na(corLong2$cor), ]
head(corLong2)## cor rowSample colSample
## 1 1.0000 R14030_H7K5NBBXX R14030_H7K5NBBXX
## 2 0.1350 R14184_H7K5NBBXX R14030_H7K5NBBXX
## 3 0.0166 R13904_H7K5NBBXX R14030_H7K5NBBXX
## 4 0.0311 R14296_H7JLCBBXX R14030_H7K5NBBXX
## 5 0.0338 R14247_HF3JYBBXX R14030_H7K5NBBXX
## 6 0.1890 R15093_HFY2MBBXX R14030_H7K5NBBXXWe can check these tables for columns where different brains are strongly correlated and where the same brain fails to match itself. Below is the output of those analysis for the TOPMed genotypes.
## cor rowSample colSample rowBrain colBrain rowBatch colBatch
## 180 0.0825 6017049081_R01C02 5535549043_R01C01 Br1652 Br1652 1M 1M
## 196 0.0501 201398400130_R04C01 5535549043_R01C01 Br1652 Br1652 2-5-8-v1-3 1M
## 467 0.0825 5535549043_R01C01 6017049081_R01C02 Br1652 Br1652 1M 1M
## 490 0.1440 201398400130_R04C01 6017049081_R01C02 Br1652 Br1652 2-5-8-v1-3 1M
## 1139 0.0501 5535549043_R01C01 201398400130_R04C01 Br1652 Br1652 1M 2-5-8-v1-3
## 1146 0.1440 6017049081_R01C02 201398400130_R04C01 Br1652 Br1652 1M 2-5-8-v1-3
## 1212 0.0379 9373406026_R02C01 201398400130_R06C01 Br2275 Br2275 5M 2-5-8-v1-3
## 1499 0.0379 201398400130_R06C01 9373406026_R02C01 Br2275 Br2275 2-5-8-v1-3 5M## [1] cor rowSample colSample rowBrain colBrain rowBatch colBatch
## <0 rows> (or 0-length row.names)And we do this again for the SPEAQeasy data.
## [1] cor rowSample colSample rowBrain colBrain
## <0 rows> (or 0-length row.names)## [1] cor rowSample colSample rowBrain colBrain
## <0 rows> (or 0-length row.names)We will next compare the correlation between the SPEAQeasy samples and the TOPMed samples. In order to do this we need to subset the genotypes for only SNPs that are common between the two. We can see that we have 656 snps common between the 42 samples.
## [1] 662 42## [1] 662 42As we did before we create a correlation matrix this time between the two data sets.
Check to correlation between SPEAQeasy and Genotype for mismatches and swaps.
## cor rowSample colSample colBrain rowBrain
## 165 0.00962 9373408026_R01C01 R14296_H7JLCBBXX Br2473 Br2473
## 425 0.11600 5535549043_R01C01 R14129_HCTYLBBXX Br1652 Br1652
## 432 0.11800 6017049081_R01C02 R14129_HCTYLBBXX Br1652 Br1652
## 498 -0.04270 9373406026_R02C01 R14222_H7JHNBBXX Br2275 Br2275
## 582 -0.03790 9373406026_R02C01 R13997_H7JHNBBXX Br2275 Br2275
## 669 0.08540 9373408026_R01C01 R14077_HCTYLBBXX Br2473 Br2473
## 917 0.04020 9373406026_R01C01 R14290_H7L3FBBXX Br2260 Br2260
## 1463 0.05050 9373406026_R01C01 R14071_HF3JYBBXX Br2260 Br2260
## 1697 0.76500 3998646040_R06C01 R14017_HF5JNBBXX Br5190 Br5190## cor rowSample colSample colBrain rowBrain
## 161 0.865 9373406026_R01C01 R14296_H7JLCBBXX Br2473 Br2260
## 665 0.815 9373406026_R01C01 R14077_HCTYLBBXX Br2473 Br2260
## 921 0.866 9373408026_R01C01 R14290_H7L3FBBXX Br2260 Br2473
## 1467 0.915 9373408026_R01C01 R14071_HF3JYBBXX Br2260 Br2473We can see from this from this analysis there are a few swaps present between RNA and DNA samples here. We can categorize them as simple and complex sample swaps. Because the two Br2275 do not match each other and also match nothing else we will be forced to consider this a complex swap and drop the sample. In the case of Br2473 it is a simple swap with Br2260 in both cases. This can be amended by swapping with in the phenotype data sheet manually. Now we have our accurate data outputs and will need to fix our ranged summarized experiment object for our SPEAQeasy data.
load(here(
"pipeline_outputs",
"count_objects",
"rse_gene_Jlab_experiment_n42.Rdata"
))
## drop sample from rse with SPEAQeasy data
ids <- pd_example$SAMPLE_ID[pd_example$BrNum == "Br2275"]
rse_gene <- rse_gene[, !rse_gene$SAMPLE_ID == ids[1]]
rse_gene <- rse_gene[, !rse_gene$SAMPLE_ID == ids[2]]
# resolve swaps and drops in pd_example
pd_example <- pd_example[!pd_example$SAMPLE_ID == ids[1], ]
pd_example <- pd_example[!pd_example$SAMPLE_ID == ids[2], ]
ids2 <- pd_example$SAMPLE_ID[pd_example$BrNum == "Br2260"]
ids3 <- pd_example$SAMPLE_ID[pd_example$BrNum == "Br2473"]
pd_example$SAMPLE_ID[pd_example$Sample_ID == ids2] <- "Br2473"
pd_example$SAMPLE_ID[pd_example$Sample_ID == ids3] <- "Br2260"
# reorder phenotype data by the sample order present in the 'rse_gene' object
pd_example <-
pd_example[match(rse_gene$SAMPLE_ID, pd_example$SAMPLE_ID), ]
# add important colData to 'rse_gene'
rse_gene$BrainRegion <- pd_example$BrainRegion
rse_gene$Race <- pd_example$Race
rse_gene$PrimaryDx <- pd_example$PrimaryDx
rse_gene$Sex <- pd_example$Sex
rse_gene$AgeDeath <- pd_example$AgeDeath
# add correct BrNum to colData for rse_gene
colData(rse_gene)$BrNum <- pd_example$BrNum
save(rse_gene, file = "rse_speaqeasy.RData")1 Reproducibility
This analysis report was made possible thanks to:
- R (Müller, 2020)
- devtools (Allaire, Xie, McPherson, Luraschi et al., 2020)
- here (Obenchain, Lawrence, Carey, Gogarten et al., 2014)
- jaffelab (Boettiger, 2021)
- knitcitations (Collado-Torres, Jaffe, and Burke, 2024)
- pheatmap (Kolde, 2019)
- rmarkdown
- SummarizedExperiment (R Core Team, 2020)
- tidyr (Morgan, Obenchain, Hester, and Pagès, 2020)
- voom
- VariantAnnotation (Xie, Dervieux, and Riederer, 2020)
[1] J. Allaire, Y. Xie, J. McPherson, J. Luraschi, et al. rmarkdown: Dynamic Documents for R. R package version 2.6. 2020. <URL: https://github.com/rstudio/rmarkdown>.
[2] C. Boettiger. knitcitations: Citations for ‘Knitr’ Markdown Files. R package version 1.0.12. 2021. <URL: https://github.com/cboettig/knitcitations>.
[3] L. Collado-Torres, A. E. Jaffe, and E. E. Burke. jaffelab: Commonly used functions by the Jaffe lab. R package version 0.99.34. 2024. <URL: https://github.com/LieberInstitute/jaffelab>.
[4] R. Kolde. pheatmap: Pretty Heatmaps. R package version 1.0.12. 2019.
[5] M. Morgan, V. Obenchain, J. Hester, and H. Pagès. SummarizedExperiment: SummarizedExperiment container. R package version 1.20.0. 2020. <URL: https://bioconductor.org/packages/SummarizedExperiment>.
[6] K. Müller. here: A Simpler Way to Find Your Files. https://here.r-lib.org/, https://github.com/r-lib/here. 2020.
[7] V. Obenchain, M. Lawrence, V. Carey, S. Gogarten, et al. “VariantAnnotation: a Bioconductor package for exploration and annotation of genetic variants”. In: Bioinformatics 30.14 (2014), pp. 2076-2078. DOI: 10.1093/bioinformatics/btu168.
[8] R Core Team. R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing. Vienna, Austria, 2020. <URL: https://www.R-project.org/>.
[9] Y. Xie, C. Dervieux, and E. Riederer. R Markdown Cookbook. ISBN 9780367563837. Boca Raton, Florida: Chapman and Hall/CRC, 2020. <URL: https://bookdown.org/yihui/rmarkdown-cookbook>.
# Time spent creating this report:
diff(c(timestart, Sys.time()))## Time difference of 1.107636 secs# Date this report was generated
message(Sys.time())## 2024-12-11 17:01:01# Reproducibility info
options(width = 120)
devtools::session_info()## ─ Session info ───────────────────────────────────────────────────────────────────────────────────────────────────────
## setting value
## version R version 4.0.3 (2020-10-10)
## os Ubuntu 20.04 LTS
## system x86_64, linux-gnu
## ui X11
## language (EN)
## collate en_US.UTF-8
## ctype en_US.UTF-8
## tz Etc/UTC
## date 2024-12-11
##
## ─ Packages ───────────────────────────────────────────────────────────────────────────────────────────────────────────
## package * version date lib source
## AnnotationDbi * 1.52.0 2020-10-27 [1] Bioconductor
## askpass 1.1 2019-01-13 [2] RSPM (R 4.0.3)
## assertthat 0.2.1 2019-03-21 [2] RSPM (R 4.0.3)
## backports 1.2.1 2020-12-09 [1] RSPM (R 4.0.3)
## base64enc 0.1-3 2015-07-28 [2] RSPM (R 4.0.3)
## bibtex 0.5.1 2024-12-11 [1] Github (ropensci/bibtex@12f8bef)
## Biobase * 2.50.0 2020-10-27 [1] Bioconductor
## BiocFileCache 1.14.0 2020-10-27 [1] Bioconductor
## BiocGenerics * 0.36.1 2021-04-16 [1] Bioconductor
## BiocManager 1.30.10 2019-11-16 [1] RSPM (R 4.0.0)
## BiocParallel 1.24.1 2020-11-06 [1] Bioconductor
## BiocStyle * 2.18.1 2020-11-24 [1] Bioconductor
## biomaRt 2.46.3 2021-02-09 [1] Bioconductor
## Biostrings * 2.58.0 2020-10-27 [1] Bioconductor
## bit 4.0.4 2020-08-04 [1] RSPM (R 4.0.5)
## bit64 4.0.5 2020-08-30 [1] RSPM (R 4.0.5)
## bitops 1.0-6 2013-08-17 [1] RSPM (R 4.0.3)
## blob 1.2.1 2020-01-20 [1] RSPM (R 4.0.3)
## bookdown 0.21 2020-10-13 [1] RSPM (R 4.0.2)
## BSgenome 1.58.0 2020-10-27 [1] Bioconductor
## bslib 0.2.4 2021-01-25 [1] RSPM (R 4.0.3)
## bumphunter 1.32.0 2020-10-27 [1] Bioconductor
## cachem 1.0.4 2021-02-13 [2] RSPM (R 4.0.3)
## callr 3.5.1 2020-10-13 [2] RSPM (R 4.0.3)
## checkmate 2.0.0 2020-02-06 [1] RSPM (R 4.0.3)
## cli 2.3.0 2021-01-31 [2] RSPM (R 4.0.3)
## cluster 2.1.1 2021-02-14 [3] RSPM (R 4.0.3)
## clusterProfiler * 3.18.1 2021-02-09 [1] Bioconductor
## codetools 0.2-18 2020-11-04 [3] RSPM (R 4.0.3)
## colorspace 2.0-0 2020-11-11 [1] RSPM (R 4.0.3)
## cowplot 1.1.1 2020-12-30 [1] RSPM (R 4.0.5)
## crayon 1.4.1 2021-02-08 [2] RSPM (R 4.0.3)
## crosstalk 1.1.1 2021-01-12 [2] RSPM (R 4.0.3)
## curl 4.3 2019-12-02 [2] RSPM (R 4.0.3)
## data.table 1.13.6 2020-12-30 [1] RSPM (R 4.0.3)
## DBI 1.1.1 2021-01-15 [1] RSPM (R 4.0.3)
## dbplyr 2.1.0 2021-02-03 [1] RSPM (R 4.0.3)
## DelayedArray 0.16.3 2021-03-24 [1] Bioconductor
## derfinder 1.24.2 2020-12-18 [1] Bioconductor
## derfinderHelper 1.24.1 2020-12-18 [1] Bioconductor
## desc 1.2.0 2018-05-01 [2] RSPM (R 4.0.3)
## devtools * 2.3.2 2020-09-18 [2] RSPM (R 4.0.3)
## digest 0.6.27 2020-10-24 [2] RSPM (R 4.0.3)
## DO.db 2.9 2024-12-11 [1] Bioconductor
## doRNG 1.8.2 2020-01-27 [1] RSPM (R 4.0.3)
## DOSE 3.16.0 2020-10-27 [1] Bioconductor
## downloader 0.4 2015-07-09 [1] RSPM (R 4.0.5)
## dplyr 1.0.4 2021-02-02 [1] RSPM (R 4.0.3)
## DT 0.17 2021-01-06 [2] RSPM (R 4.0.3)
## edgeR * 3.32.1 2021-01-14 [1] Bioconductor
## ellipsis 0.3.1 2020-05-15 [2] RSPM (R 4.0.3)
## enrichplot * 1.10.2 2021-01-28 [1] Bioconductor
## evaluate 0.14 2019-05-28 [2] RSPM (R 4.0.3)
## ExploreModelMatrix * 1.2.0 2020-10-27 [1] Bioconductor
## farver 2.0.3 2020-01-16 [1] RSPM (R 4.0.3)
## fastmap 1.1.0 2021-01-25 [2] RSPM (R 4.0.3)
## fastmatch 1.1-0 2017-01-28 [1] RSPM (R 4.0.3)
## fgsea 1.16.0 2020-10-27 [1] Bioconductor
## foreach 1.5.1 2020-10-15 [1] RSPM (R 4.0.3)
## foreign 0.8-81 2020-12-22 [3] RSPM (R 4.0.3)
## Formula 1.2-4 2020-10-16 [1] RSPM (R 4.0.3)
## fs 1.5.0 2020-07-31 [2] RSPM (R 4.0.3)
## generics 0.1.0 2020-10-31 [1] RSPM (R 4.0.3)
## GenomeInfoDb * 1.26.7 2021-04-08 [1] Bioconductor
## GenomeInfoDbData 1.2.4 2024-12-11 [1] Bioconductor
## GenomicAlignments 1.26.0 2020-10-27 [1] Bioconductor
## GenomicFeatures 1.42.3 2021-04-01 [1] Bioconductor
## GenomicFiles 1.26.0 2020-10-27 [1] Bioconductor
## GenomicRanges * 1.42.0 2020-10-27 [1] Bioconductor
## GEOquery 2.58.0 2020-10-27 [1] Bioconductor
## ggforce 0.3.2 2020-06-23 [1] RSPM (R 4.0.3)
## ggnewscale 0.4.5 2021-01-11 [1] RSPM (R 4.0.3)
## ggplot2 * 3.3.3 2020-12-30 [1] RSPM (R 4.0.3)
## ggraph 2.0.4 2020-11-16 [1] RSPM (R 4.0.3)
## ggrepel 0.9.1 2021-01-15 [1] RSPM (R 4.0.3)
## glue 1.4.2 2020-08-27 [2] RSPM (R 4.0.3)
## GO.db 3.12.1 2024-12-11 [1] Bioconductor
## googledrive 1.0.1 2020-05-05 [1] RSPM (R 4.0.0)
## GOSemSim 2.16.1 2020-10-29 [1] Bioconductor
## graphlayouts 0.7.1 2020-10-26 [1] RSPM (R 4.0.3)
## gridExtra 2.3 2017-09-09 [1] RSPM (R 4.0.5)
## gtable 0.3.0 2019-03-25 [1] RSPM (R 4.0.3)
## here * 1.0.1 2020-12-13 [1] RSPM (R 4.0.5)
## highr 0.8 2019-03-20 [2] RSPM (R 4.0.3)
## Hmisc 4.4-2 2020-11-29 [1] RSPM (R 4.0.3)
## hms 1.0.0 2021-01-13 [1] RSPM (R 4.0.3)
## htmlTable 2.1.0 2020-09-16 [1] RSPM (R 4.0.3)
## htmltools 0.5.1.1 2021-01-22 [2] RSPM (R 4.0.3)
## htmlwidgets 1.5.3 2020-12-10 [2] RSPM (R 4.0.3)
## httpuv 1.5.5 2021-01-13 [1] RSPM (R 4.0.3)
## httr 1.4.2 2020-07-20 [2] RSPM (R 4.0.3)
## igraph 1.2.6 2020-10-06 [1] RSPM (R 4.0.3)
## IRanges * 2.24.1 2020-12-12 [1] Bioconductor
## iterators 1.0.13 2020-10-15 [1] RSPM (R 4.0.3)
## jaffelab * 0.99.34 2024-12-11 [1] Github (LieberInstitute/jaffelab@a68c146)
## jpeg 0.1-8.1 2019-10-24 [1] RSPM (R 4.0.3)
## jquerylib 0.1.3 2020-12-17 [1] RSPM (R 4.0.3)
## jsonlite 1.7.2 2020-12-09 [2] RSPM (R 4.0.3)
## knitcitations * 1.0.12 2021-01-10 [1] RSPM (R 4.0.3)
## knitr 1.31 2021-01-27 [2] RSPM (R 4.0.3)
## labeling 0.4.2 2020-10-20 [1] RSPM (R 4.0.3)
## later 1.1.0.1 2020-06-05 [2] RSPM (R 4.0.3)
## lattice 0.20-41 2020-04-02 [3] CRAN (R 4.0.3)
## latticeExtra 0.6-29 2019-12-19 [1] RSPM (R 4.0.3)
## lazyeval 0.2.2 2019-03-15 [2] RSPM (R 4.0.3)
## lifecycle 1.0.0 2021-02-15 [2] RSPM (R 4.0.3)
## limma * 3.46.0 2020-10-27 [1] Bioconductor
## locfit 1.5-9.4 2020-03-25 [1] RSPM (R 4.0.3)
## lubridate 1.7.9.2 2020-11-13 [1] RSPM (R 4.0.3)
## magrittr 2.0.1 2020-11-17 [2] RSPM (R 4.0.3)
## MASS 7.3-53.1 2021-02-12 [3] RSPM (R 4.0.3)
## Matrix 1.3-2 2021-01-06 [3] RSPM (R 4.0.3)
## MatrixGenerics * 1.2.1 2021-01-30 [1] Bioconductor
## matrixStats * 0.58.0 2021-01-29 [1] RSPM (R 4.0.3)
## memoise 2.0.0 2021-01-26 [2] RSPM (R 4.0.3)
## mime 0.10 2021-02-13 [2] RSPM (R 4.0.3)
## munsell 0.5.0 2018-06-12 [1] RSPM (R 4.0.3)
## nnet 7.3-15 2021-01-24 [3] RSPM (R 4.0.3)
## openssl 1.4.3 2020-09-18 [2] RSPM (R 4.0.3)
## org.Hs.eg.db * 3.12.0 2024-12-11 [1] Bioconductor
## pheatmap * 1.0.12 2019-01-04 [1] RSPM (R 4.0.5)
## pillar 1.4.7 2020-11-20 [2] RSPM (R 4.0.3)
## pkgbuild 1.2.0 2020-12-15 [2] RSPM (R 4.0.3)
## pkgconfig 2.0.3 2019-09-22 [2] RSPM (R 4.0.3)
## pkgload 1.1.0 2020-05-29 [2] RSPM (R 4.0.3)
## plotly * 4.9.3 2021-01-10 [1] RSPM (R 4.0.3)
## plyr 1.8.6 2020-03-03 [1] RSPM (R 4.0.3)
## png 0.1-7 2013-12-03 [1] RSPM (R 4.0.3)
## polyclip 1.10-0 2019-03-14 [1] RSPM (R 4.0.3)
## prettyunits 1.1.1 2020-01-24 [2] RSPM (R 4.0.3)
## processx 3.4.5 2020-11-30 [2] RSPM (R 4.0.3)
## progress 1.2.2 2019-05-16 [1] RSPM (R 4.0.3)
## promises 1.2.0.1 2021-02-11 [2] RSPM (R 4.0.3)
## ps 1.5.0 2020-12-05 [2] RSPM (R 4.0.3)
## purrr 0.3.4 2020-04-17 [2] RSPM (R 4.0.3)
## qvalue 2.22.0 2020-10-27 [1] Bioconductor
## R.methodsS3 1.8.1 2020-08-26 [1] RSPM (R 4.0.3)
## R.oo 1.24.0 2020-08-26 [1] RSPM (R 4.0.3)
## R.utils 2.10.1 2020-08-26 [1] RSPM (R 4.0.3)
## R6 2.5.0 2020-10-28 [2] RSPM (R 4.0.3)
## rafalib * 1.0.0 2015-08-09 [1] RSPM (R 4.0.0)
## rappdirs 0.3.3 2021-01-31 [2] RSPM (R 4.0.3)
## RColorBrewer * 1.1-2 2014-12-07 [1] RSPM (R 4.0.3)
## Rcpp 1.0.6 2021-01-15 [2] RSPM (R 4.0.3)
## RCurl 1.98-1.2 2020-04-18 [1] RSPM (R 4.0.3)
## readr 1.4.0 2020-10-05 [1] RSPM (R 4.0.3)
## recount * 1.16.1 2020-12-18 [1] Bioconductor
## RefManageR 1.4.3 2024-12-11 [1] Github (ropensci/RefManageR@d616da5)
## remotes 2.2.0 2020-07-21 [2] RSPM (R 4.0.3)
## rentrez 1.2.3 2020-11-10 [1] RSPM (R 4.0.5)
## reshape2 1.4.4 2020-04-09 [1] RSPM (R 4.0.3)
## rintrojs 0.2.2 2019-05-29 [1] RSPM (R 4.0.0)
## rlang 0.4.10 2020-12-30 [2] RSPM (R 4.0.3)
## rmarkdown 2.6 2020-12-14 [1] RSPM (R 4.0.3)
## rngtools 1.5 2020-01-23 [1] RSPM (R 4.0.3)
## rpart 4.1-15 2019-04-12 [3] CRAN (R 4.0.3)
## rprojroot 2.0.2 2020-11-15 [2] RSPM (R 4.0.3)
## Rsamtools * 2.6.0 2020-10-27 [1] Bioconductor
## RSQLite 2.2.3 2021-01-24 [1] RSPM (R 4.0.3)
## rstudioapi 0.13 2020-11-12 [2] RSPM (R 4.0.3)
## rtracklayer 1.50.0 2020-10-27 [1] Bioconductor
## rvcheck 0.1.8 2020-03-01 [1] RSPM (R 4.0.0)
## S4Vectors * 0.28.1 2020-12-09 [1] Bioconductor
## sass 0.3.1 2021-01-24 [1] RSPM (R 4.0.3)
## scales 1.1.1 2020-05-11 [1] RSPM (R 4.0.3)
## scatterpie 0.1.5 2020-09-09 [1] RSPM (R 4.0.2)
## segmented 1.3-2 2021-02-09 [1] RSPM (R 4.0.3)
## sessioninfo 1.1.1 2018-11-05 [1] RSPM (R 4.0.3)
## shadowtext 0.0.7 2019-11-06 [1] RSPM (R 4.0.0)
## shiny 1.6.0 2021-01-25 [1] RSPM (R 4.0.3)
## shinydashboard 0.7.1 2018-10-17 [1] RSPM (R 4.0.3)
## shinyjs 2.0.0 2020-09-09 [1] RSPM (R 4.0.3)
## statmod 1.4.35 2020-10-19 [1] RSPM (R 4.0.3)
## stringi 1.5.3 2020-09-09 [2] RSPM (R 4.0.3)
## stringr 1.4.0 2019-02-10 [2] RSPM (R 4.0.3)
## SummarizedExperiment * 1.20.0 2020-10-27 [1] Bioconductor
## survival 3.2-7 2020-09-28 [3] CRAN (R 4.0.3)
## testthat 3.0.2 2021-02-14 [2] RSPM (R 4.0.3)
## tibble 3.0.6 2021-01-29 [2] RSPM (R 4.0.3)
## tidygraph 1.2.0 2020-05-12 [1] RSPM (R 4.0.3)
## tidyr * 1.1.2 2020-08-27 [1] RSPM (R 4.0.3)
## tidyselect 1.1.0 2020-05-11 [1] RSPM (R 4.0.3)
## tweenr 1.0.1 2018-12-14 [1] RSPM (R 4.0.3)
## usethis * 2.0.1 2021-02-10 [1] RSPM (R 4.0.3)
## VariantAnnotation * 1.36.0 2020-10-27 [1] Bioconductor
## vctrs 0.3.6 2020-12-17 [2] RSPM (R 4.0.3)
## viridis 0.5.1 2018-03-29 [1] RSPM (R 4.0.3)
## viridisLite 0.3.0 2018-02-01 [1] RSPM (R 4.0.3)
## withr 2.4.1 2021-01-26 [2] RSPM (R 4.0.3)
## xfun 0.21 2021-02-10 [2] RSPM (R 4.0.3)
## XML 3.99-0.5 2020-07-23 [1] RSPM (R 4.0.3)
## xml2 1.3.2 2020-04-23 [2] RSPM (R 4.0.3)
## xtable 1.8-4 2019-04-21 [1] RSPM (R 4.0.5)
## XVector * 0.30.0 2020-10-27 [1] Bioconductor
## yaml 2.2.1 2020-02-01 [2] RSPM (R 4.0.3)
## zlibbioc 1.36.0 2020-10-27 [1] Bioconductor
##
## [1] /__w/_temp/Library
## [2] /usr/local/lib/R/site-library
## [3] /usr/local/lib/R/library