Guide to Multi-Gene Plots
Nicholas J. Eagles
Lieber Institute for Brain Development, Johns Hopkins Medical Campusnickeagles77@gmail.com
Leonardo Collado-Torres
Lieber Institute for Brain Development, Johns Hopkins Medical CampusDepartment of Biostatistics, Johns Hopkins Bloomberg School of Public Healthlcolladotor@gmail.com
27 March 2026
Source:vignettes/multi_gene_plots.Rmd
multi_gene_plots.RmdOne of the goals of spatialLIBD is to provide options
for visualizing Visium data by 10x Genomics. In particular,
vis_gene() and vis_clus() allow plotting of
individual continuous or discrete quantities belonging to each Visium
spot, in a spatially accurate manner and optionally atop histology
images.
This vignette explores a more complex capability of
vis_gene(): to visualize a summary metric of several
continuous variables simultaneously. We’ll start with a basic one-gene
use case for vis_gene() before moving to more advanced
cases.
First, let’s load some example data for us to work on. This data is a subset from a recent publication with Visium data from the dorsolateral prefrontal cortex (DLPFC) (Huuki-Myers, Spangler, Eagles, Montgomergy, Kwon, Guo, Grant-Peters, Divecha, Tippani, Sriworarat, Nguyen, Ravichandran, Tran, Seyedian, Consortium, Hyde, Kleinman, Battle, Page, Ryten, Hicks, Martinowich, Collado-Torres, and Maynard, 2024).
library("spatialLIBD")
spe <- fetch_data(type = "spatialDLPFC_Visium_example_subset")
spe
#> class: SpatialExperiment
#> dim: 28916 12107
#> metadata(1): BayesSpace.data
#> assays(2): counts logcounts
#> rownames(28916): ENSG00000243485 ENSG00000238009 ... ENSG00000278817
#> ENSG00000277196
#> rowData names(7): source type ... gene_type gene_search
#> colnames(12107): AAACAAGTATCTCCCA-1 AAACACCAATAACTGC-1 ...
#> TTGTTTGTATTACACG-1 TTGTTTGTGTAAATTC-1
#> colData names(155): age array_col ... VistoSeg_proportion wrinkle_type
#> reducedDimNames(8): 10x_pca 10x_tsne ... HARMONY UMAP.HARMONY
#> mainExpName: NULL
#> altExpNames(0):
#> spatialCoords names(2) : pxl_col_in_fullres pxl_row_in_fullres
#> imgData names(4): sample_id image_id data scaleFactorNext, let’s define several genes known to be markers for white matter (Tran, Maynard, Spangler, Huuki, Montgomery, Sadashivaiah, Tippani, Barry, Hancock, Hicks, Kleinman, Hyde, Collado-Torres, Jaffe, and Martinowich, 2021).
white_matter_genes <- c("GFAP", "AQP4", "MBP", "PLP1")
white_matter_genes <- rowData(spe)$gene_search[
rowData(spe)$gene_name %in% white_matter_genes
]
## Our list of white matter genes
white_matter_genes
#> [1] "GFAP; ENSG00000131095" "AQP4; ENSG00000171885" "MBP; ENSG00000197971"
#> [4] "PLP1; ENSG00000123560"Plotting One Gene
A typical use of vis_gene() involves plotting the
spatial distribution of a single gene or continuous variable of
interest. For example, let’s plot just the expression of
GFAP.
vis_gene(
spe,
geneid = white_matter_genes[1],
point_size = 1.5
)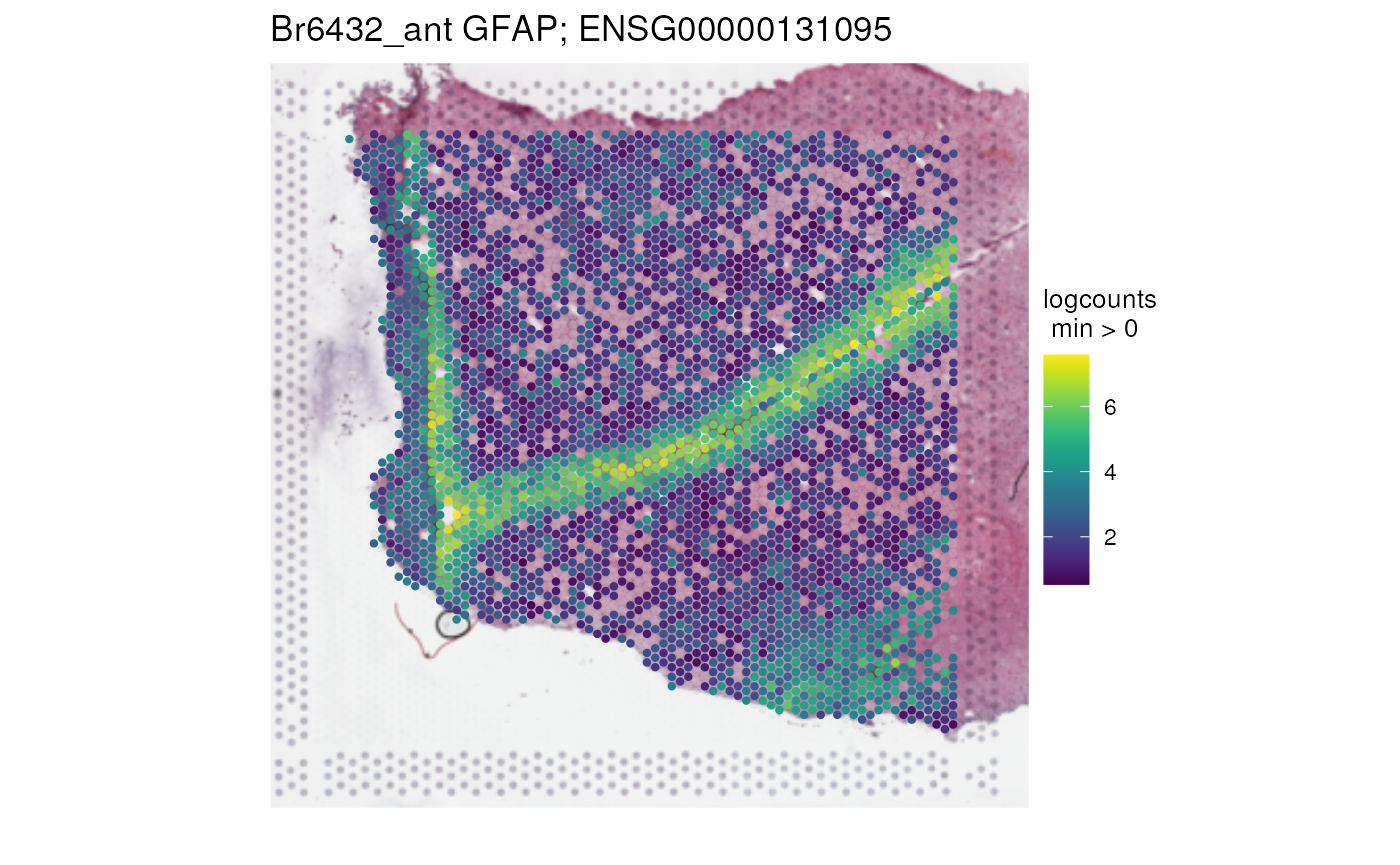
We can see a little V shaped section with higher expression of this gene. This seems to mark the location of layer 1. The bottom right corner seems to mark the location of white matter.
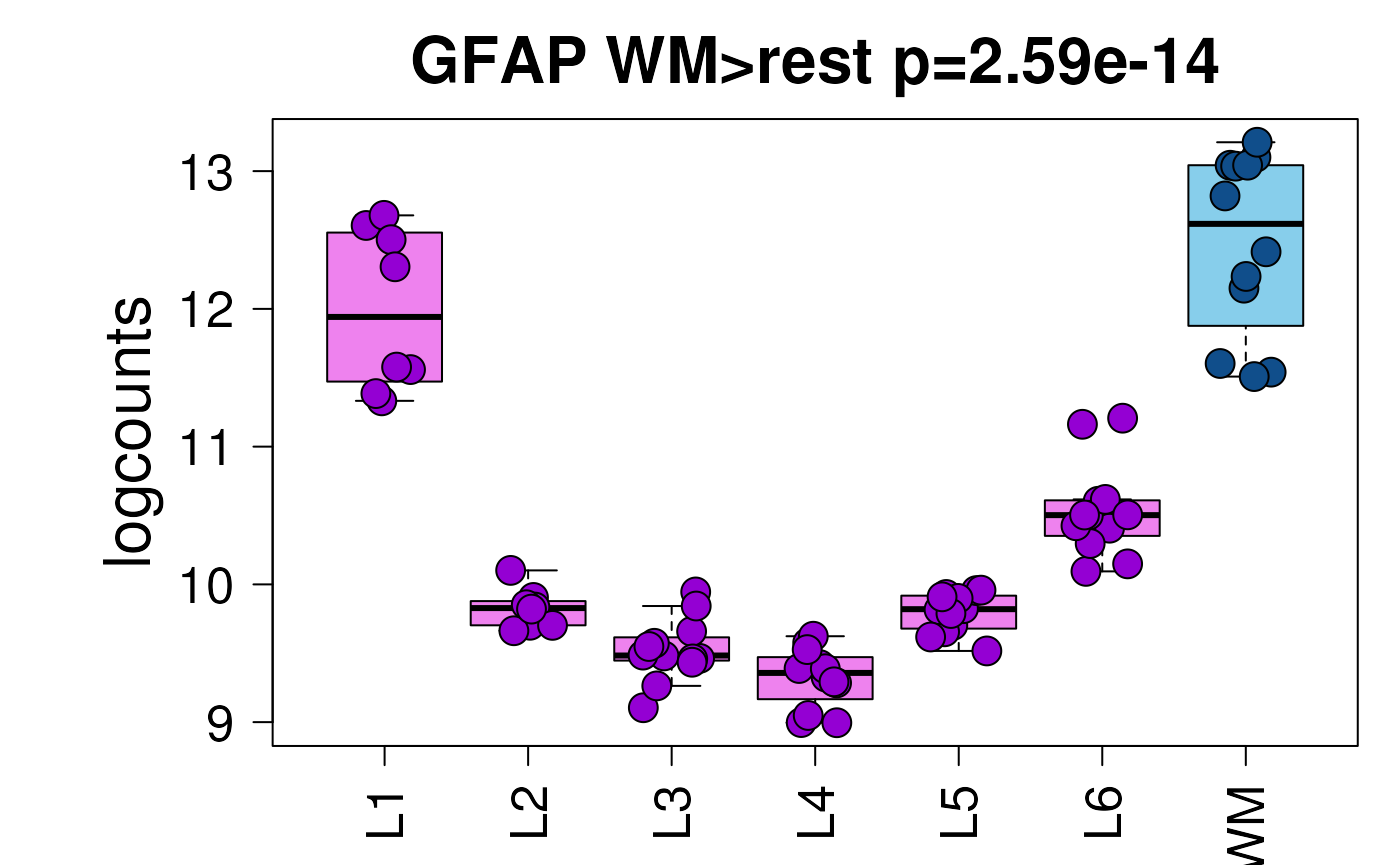
This particular gene is known to have high expression in both layer 1 and white matter in the dorsolateral prefrontal cortex as can be seen below (Maynard, Collado-Torres, Weber, Uytingco, Barry, Williams, II, Tran, Besich, Tippani, Chew, Yin, Kleinman, Hyde, Rao, Hicks, Martinowich, and Jaffe, 2021). It’s the 386th highest ranked white matter marker gene based on the enrichment test.
modeling_results <- fetch_data(type = "modeling_results")
#> 2026-03-27 00:09:58.250374 loading file /github/home/.cache/R/BiocFileCache/f2e71d5f5d9_Human_DLPFC_Visium_modeling_results.Rdata%3Fdl%3D1
sce_layer <- fetch_data(type = "sce_layer")
#> 2026-03-27 00:09:59.102177 loading file /github/home/.cache/R/BiocFileCache/f2e647b6693_Human_DLPFC_Visium_processedData_sce_scran_sce_layer_spatialLIBD.Rdata%3Fdl%3D1
sig_genes <- sig_genes_extract_all(
n = 400,
modeling_results = modeling_results,
sce_layer = sce_layer
)
i_gfap <- subset(sig_genes, gene == "GFAP" &
test == "WM")$top
i_gfap
#> [1] 386
set.seed(20200206)
layer_boxplot(
i = i_gfap,
sig_genes = sig_genes,
sce_layer = sce_layer
)
Plotting Multiple Genes
As of version 1.15.2, the geneid parameter to
vis_gene() may also take a vector of genes or continuous
variables in colData(spe). In this way, the expression of
multiple continuous variables can be summarized into a single value for
each spot, displayed just as a single input for geneid
would be. spatialLIBD provides three methods for merging
the information from multiple continuous variables, which may be
specified through the multi_gene_method parameter to
vis_gene().
Averaging Z-scores
The default is multi_gene_method = "z_score".
Essentially, each continuous variable (could be a mix of genes with
spot-level covariates) is normalized to be a Z-score by centering and
scaling. If a particular spot has a value of 1 for a
particular continuous variable, this would indicate that spot has
expression one standard deviation above the mean expression across all
spots for that continuous variable. Next, for each spot, Z-scores are
averaged across continuous variables. Compared to simply averaging raw
gene expression across genes, the "z_score" method is
insensitive to absolute expression levels (highly expressed genes don’t
dominate plots), and instead focuses on how each gene varies spatially,
weighting each gene equally.
Let’s plot all four white matter genes using this method.
vis_gene(
spe,
geneid = white_matter_genes,
multi_gene_method = "z_score",
point_size = 1.5
)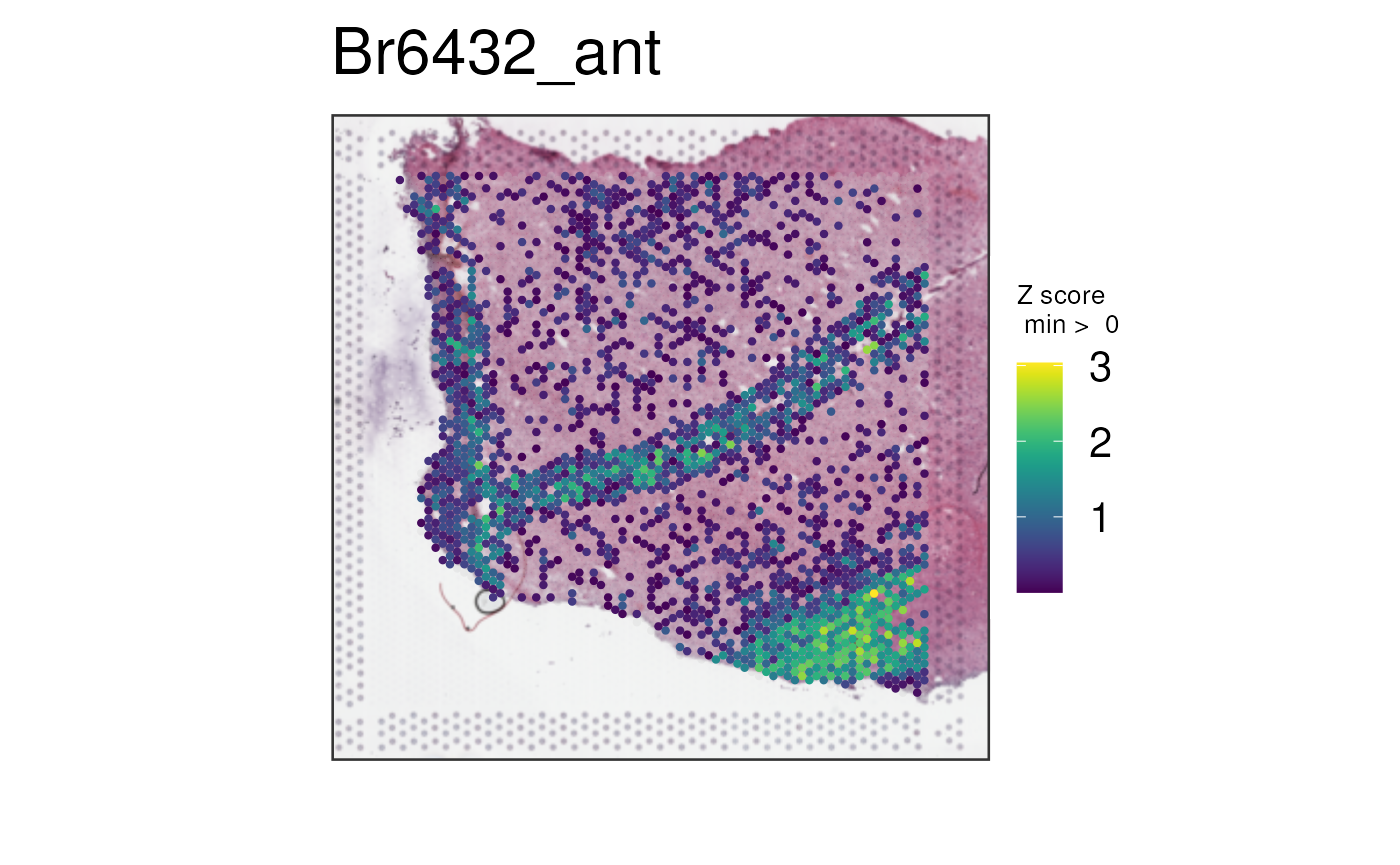
Now the bottom right corner where the white matter is located starts to pop up more, though the mixed layer 1 and white matter signal provided by GFAP is still noticeable (the V shape).
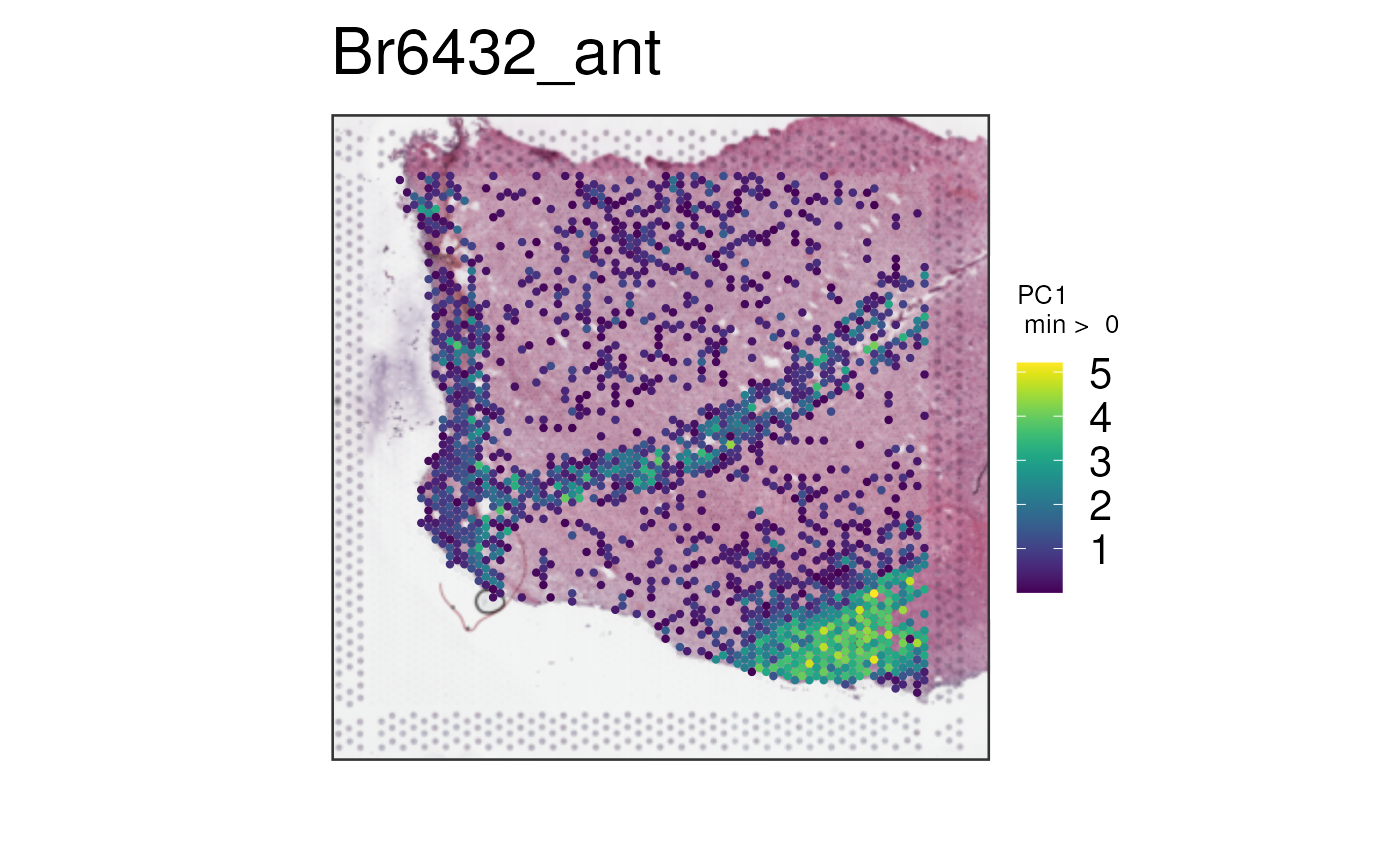
Summarizing with PCA
Another option is multi_gene_method = "pca". A matrix is
formed, where genes or continuous features are columns, and spots are
rows. PCA is performed, and the first principal component is plotted
spatially. The idea is that the first PC captures the dominant spatial
signature of the feature set. Next, its direction is reversed if the
majority of coefficients (from the “rotation matrix”) across features
are negative. When the features are genes whose expression is highly
correlated (like our white-matter-gene example!), this optional reversal
encourages higher values in the plot to represent areas of higher
expression of the features. For our case, this leads to the intuitive
result that “expression” is higher in white matter for white-matter
genes, which is not otherwise guaranteed (the “sign” of PCs is
arbitrary)!
vis_gene(
spe,
geneid = white_matter_genes,
multi_gene_method = "pca",
point_size = 1.5
)
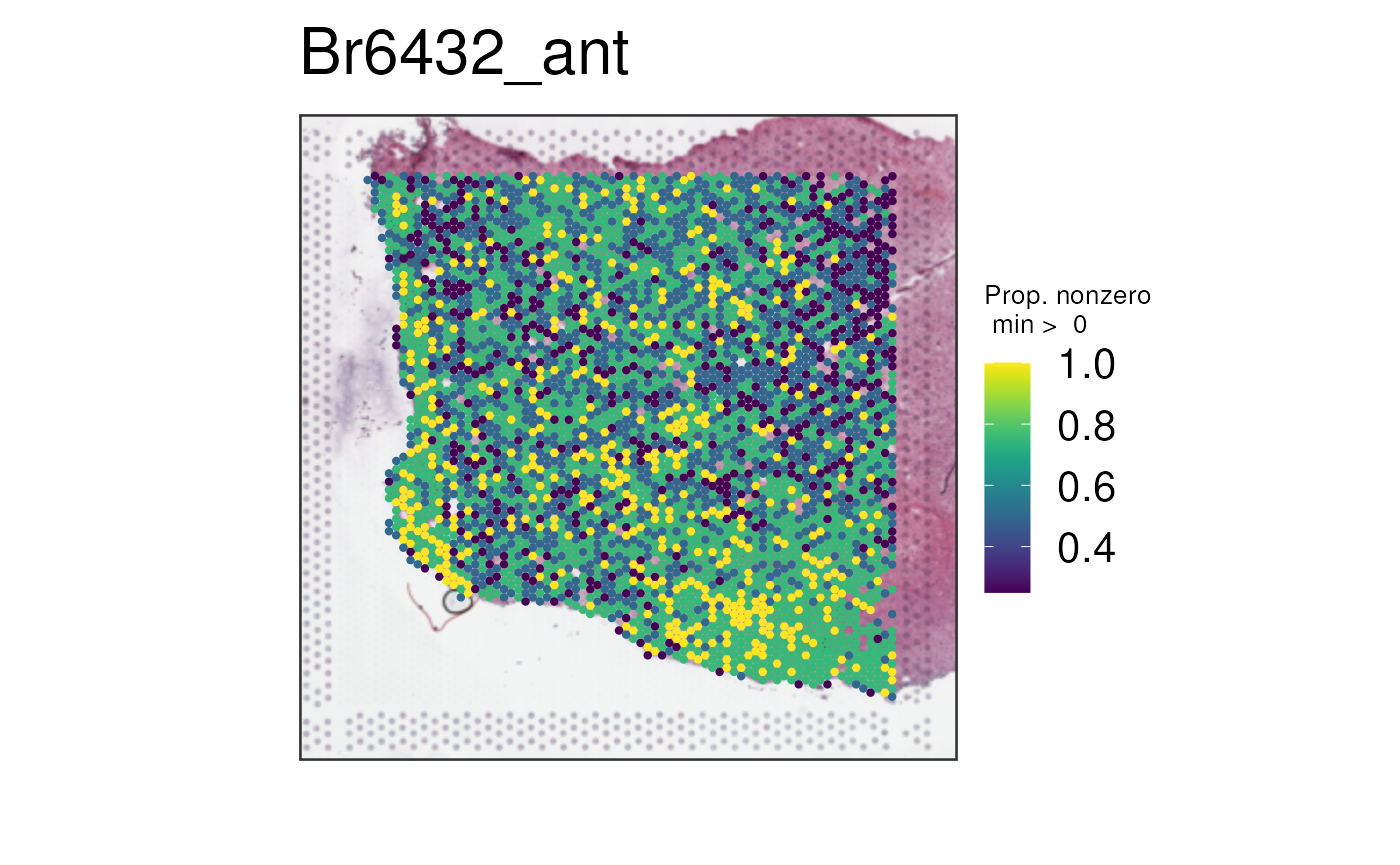
Plotting Sparsity of Expression
This final option is multi_gene_method = "sparsity". For
each spot, the proportion of features with positive expression is
plotted. This method is typically only meaningful when features are raw
gene counts that are expected to be quite sparse (have zero counts) at
certain regions of the tissue and not others. It also performs better
with a larger number of genes; with our example of four white-matter
genes, the proportion may only hold values of 0, 0.25, 0.5, 0.75, and 1,
which is not visually informative.
The white-matter example is thus poor due to lack of sparsity and low number of genes as you can see below.
vis_gene(
spe,
geneid = white_matter_genes,
multi_gene_method = "sparsity",
point_size = 1.5
)
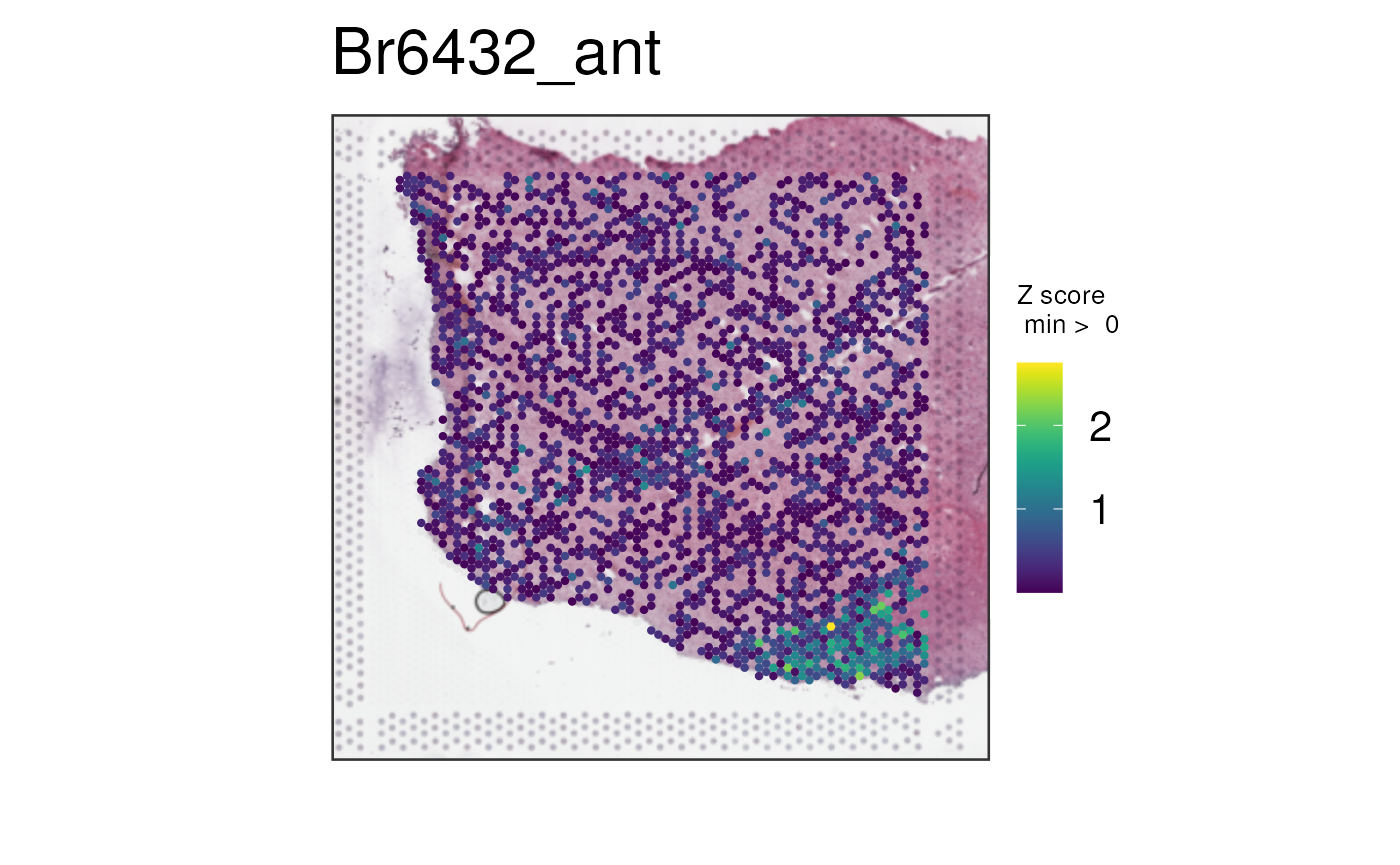
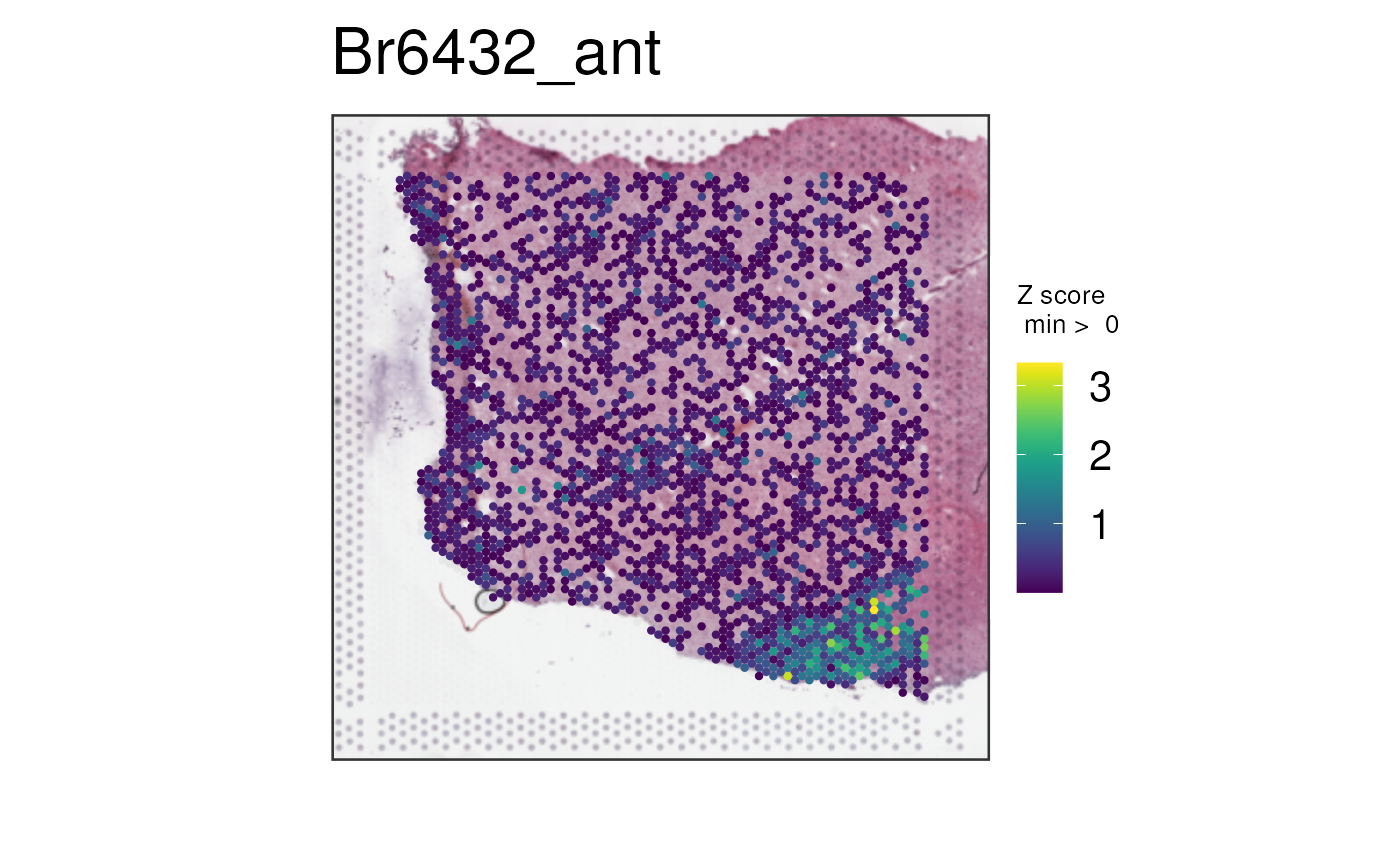
With more marker genes
Below we can plot via multi_gene_method = "z_score" the
top 25 or top 50 white matter marker genes identified via the enrichment
test in a previous dataset (Maynard, Collado-Torres, Weber et al.,
2021).
vis_gene(
spe,
geneid = subset(sig_genes, test == "WM")$ensembl[seq_len(25)],
multi_gene_method = "z_score",
point_size = 1.5
)
vis_gene(
spe,
geneid = subset(sig_genes, test == "WM")$ensembl[seq_len(50)],
multi_gene_method = "z_score",
point_size = 1.5
)
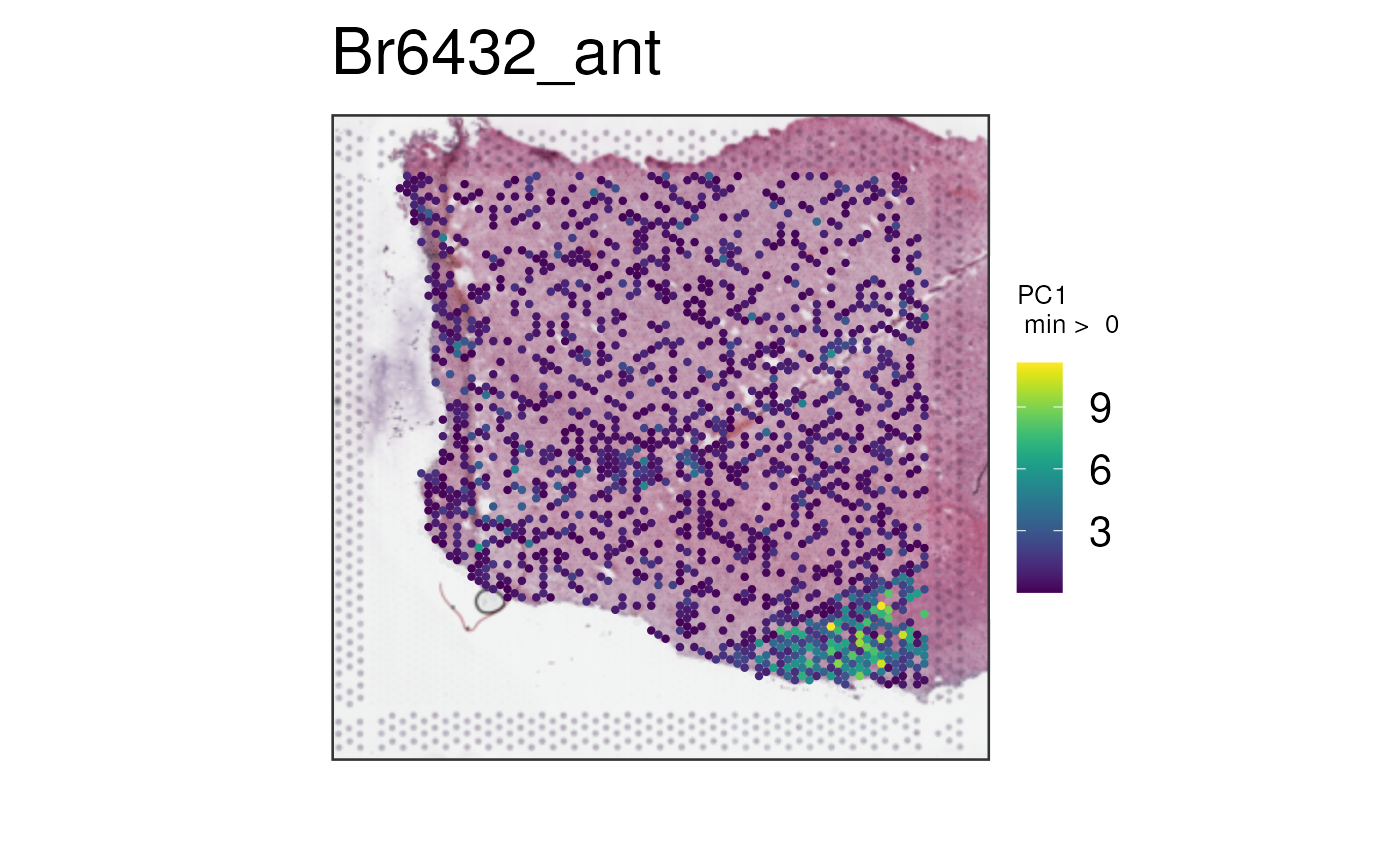
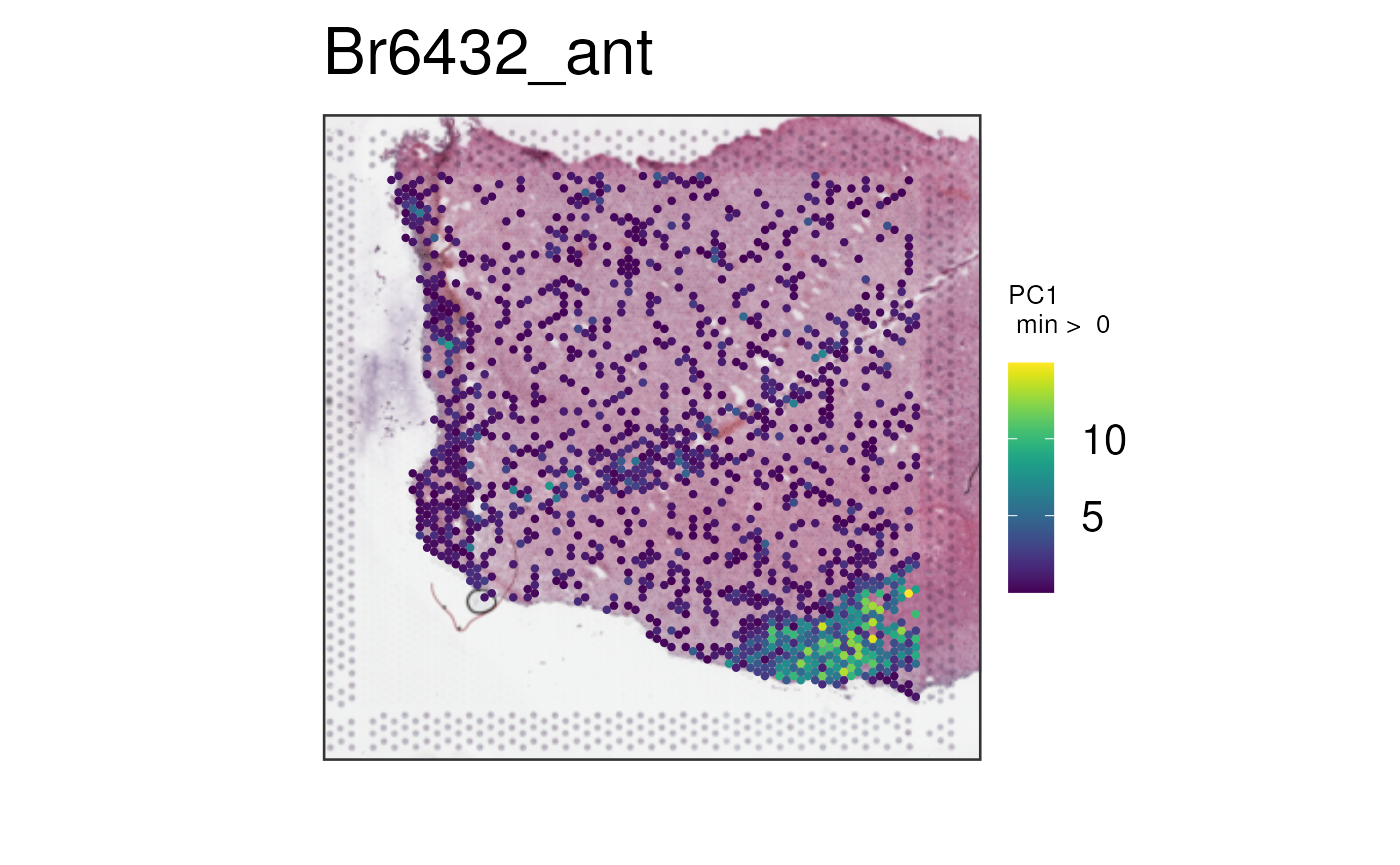
We can repeat this process for
multi_gene_method = "pca".
vis_gene(
spe,
geneid = subset(sig_genes, test == "WM")$ensembl[seq_len(25)],
multi_gene_method = "pca",
point_size = 1.5
)
vis_gene(
spe,
geneid = subset(sig_genes, test == "WM")$ensembl[seq_len(50)],
multi_gene_method = "pca",
point_size = 1.5
)
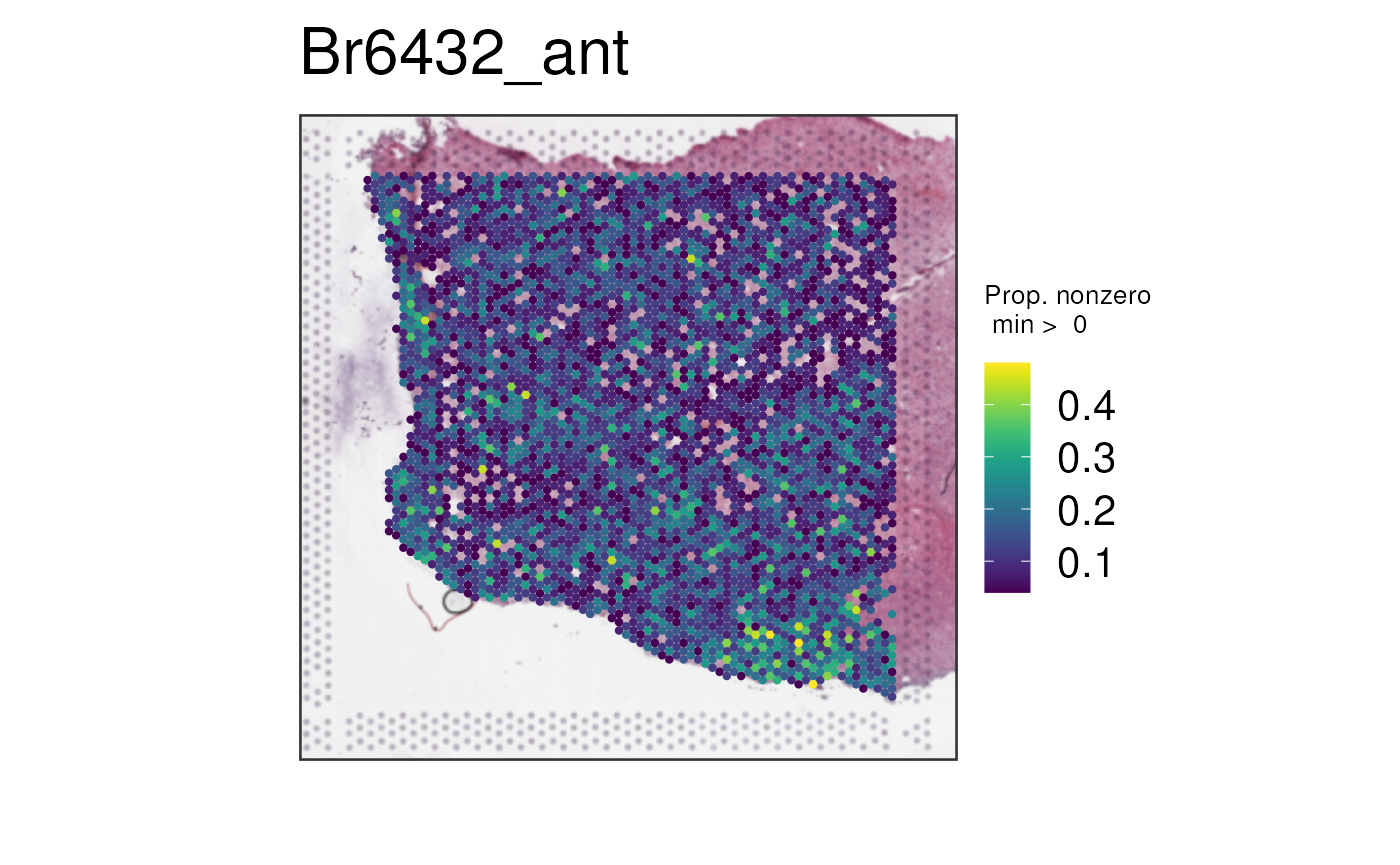
And finally, lets look at the results of
multi_gene_method = "sparsity".
vis_gene(
spe,
geneid = subset(sig_genes, test == "WM")$ensembl[seq_len(25)],
multi_gene_method = "sparsity",
point_size = 1.5
)
vis_gene(
spe,
geneid = subset(sig_genes, test == "WM")$ensembl[seq_len(50)],
multi_gene_method = "sparsity",
point_size = 1.5
)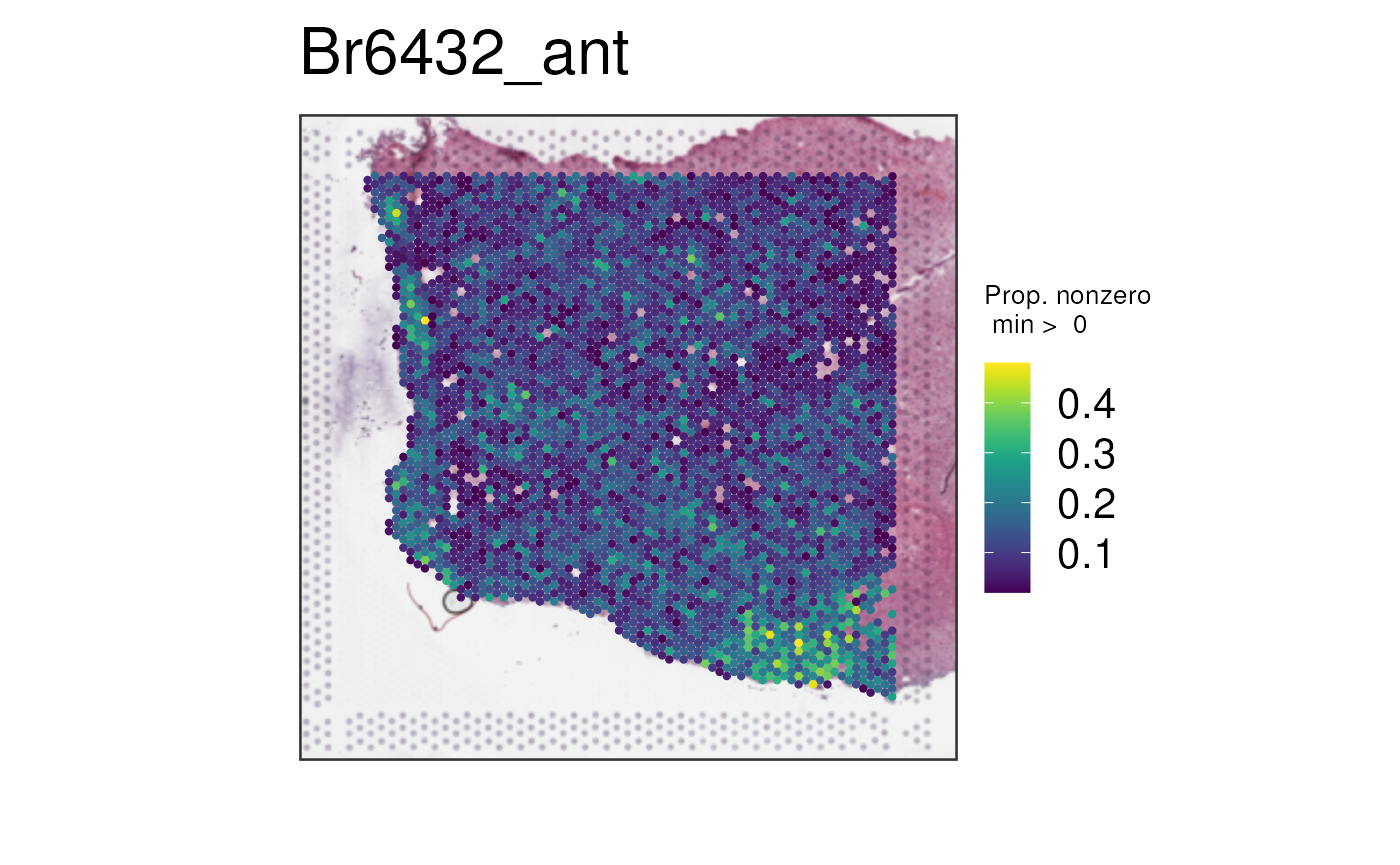
In this case, it seems that for both the top 25 or top 50 marker
genes, z_score and pca provided cleaner
visualizations than sparsity. Give them a try on your own
datasets!
Visualizing non-gene continuous variables
So far, we have only visualized multiple genes. But these methods can
be applied to several continuous variables stored in
colData(spe) as shown below.
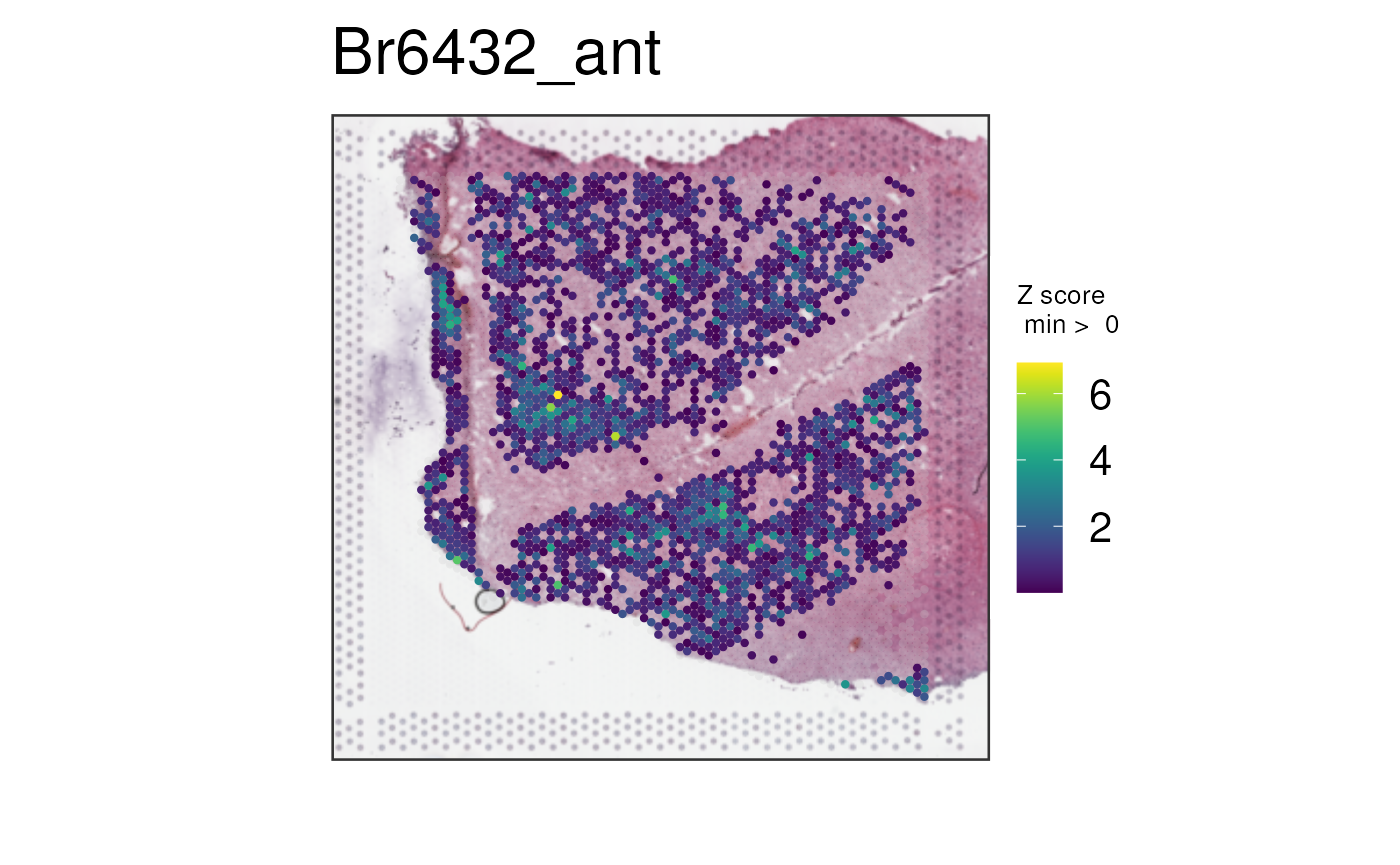
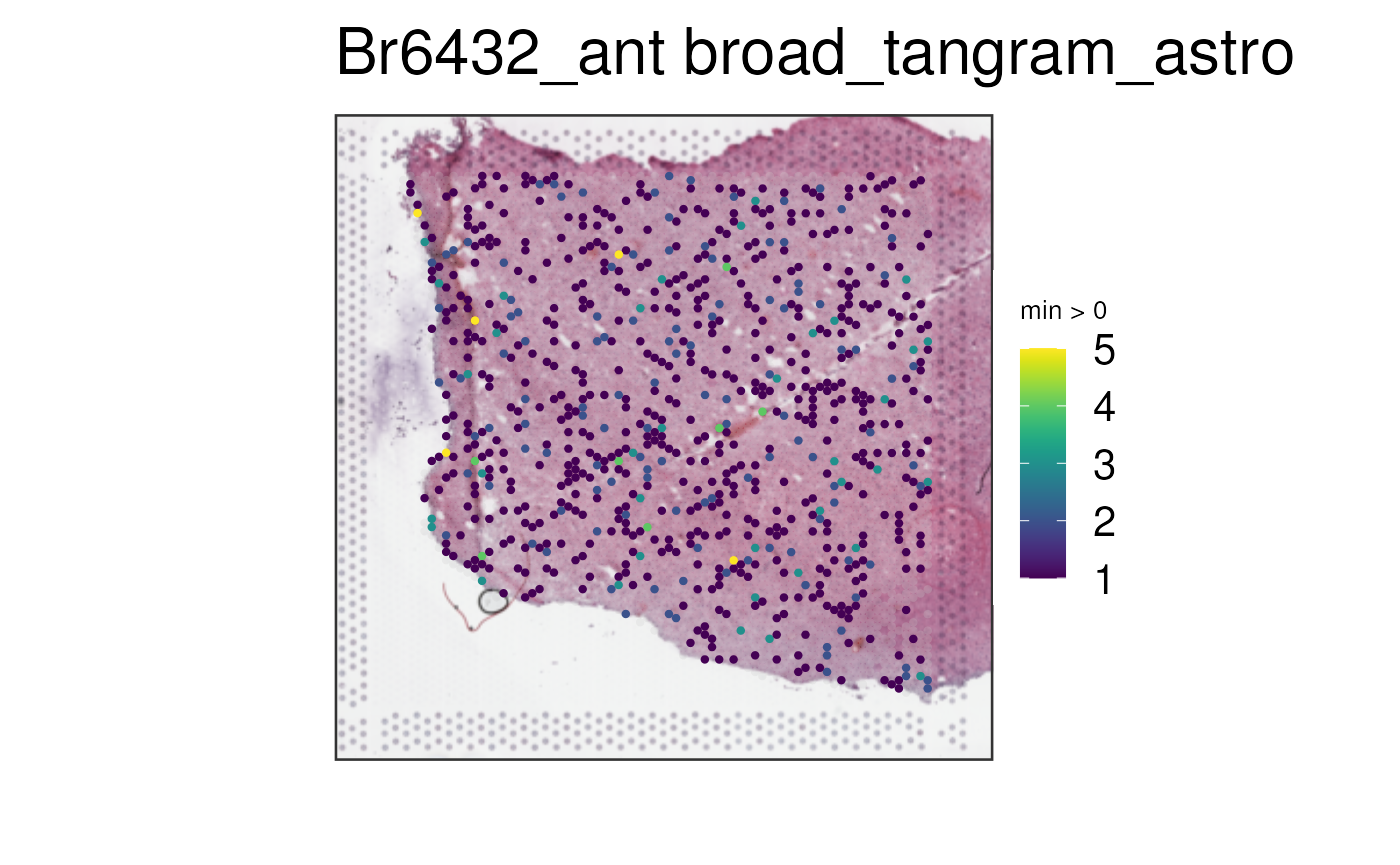
We can also combine continuous variables from
colData(spe) along with actual genes. We can combine for
example the expression of GFAP, which is a known astrocyte
marker gene, with the spot deconvolution results for astrocytes computed
using Tangram (Huuki-Myers, Spangler, Eagles et al., 2024).
vis_gene(
spe,
geneid = c("broad_tangram_astro", white_matter_genes[1]),
multi_gene_method = "pca",
point_size = 1.5
)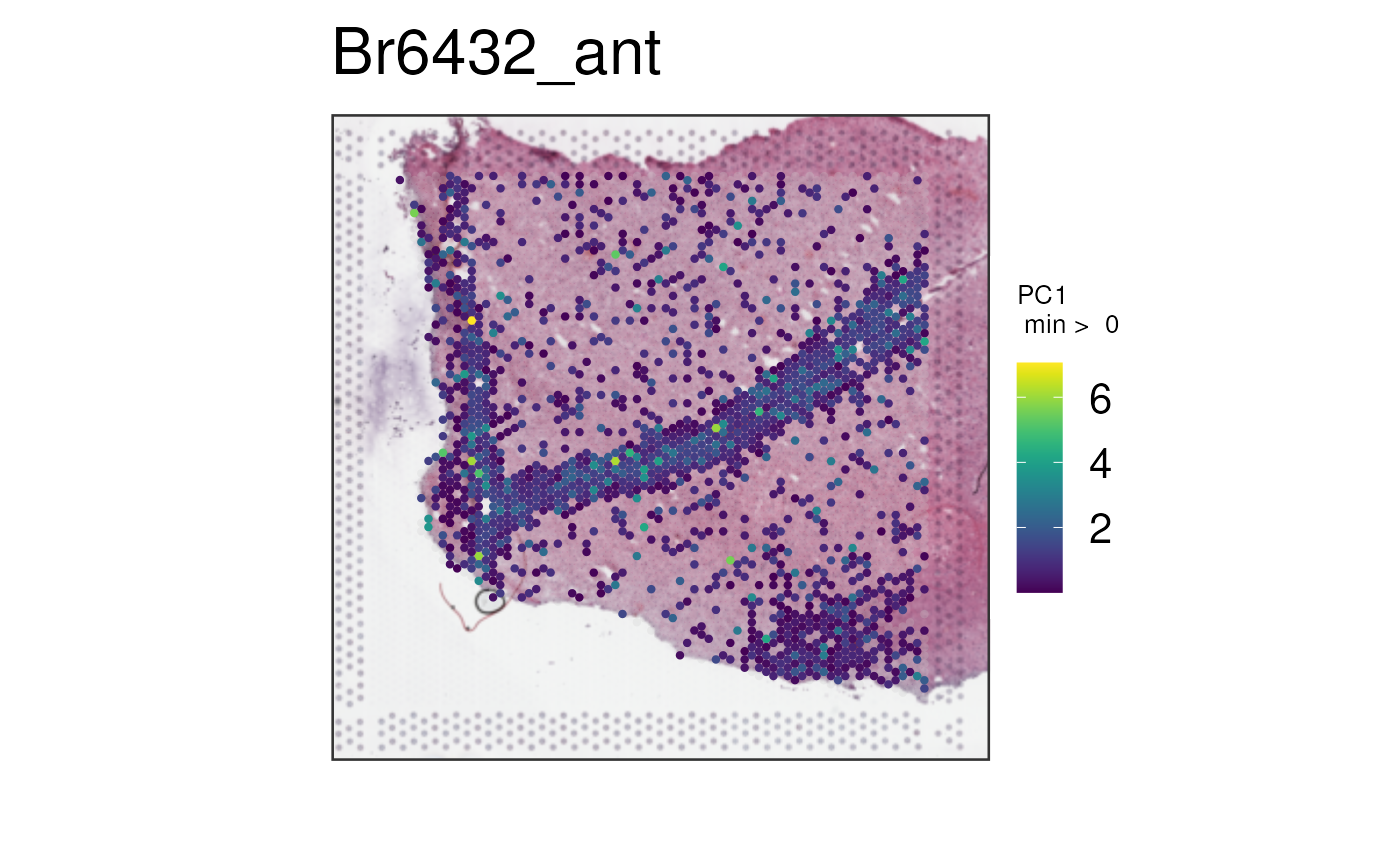
These tools enable you to further explore your data in new ways. Have fun using them!
Reproducibility
Code for creating the vignette
## Create the vignette
library("rmarkdown")
system.time(render("multi_gene_plots.Rmd"))
## Extract the R code
library("knitr")
knit("multi_gene_plots.Rmd", tangle = TRUE)Date the vignette was generated.
#> [1] "2026-03-27 00:10:15 UTC"Wallclock time spent generating the vignette.
#> Time difference of 37.41 secsR session information.
#> ─ Session info ───────────────────────────────────────────────────────────────────────────────────────────────────────
#> setting value
#> version R version 4.5.2 (2025-10-31)
#> os Ubuntu 24.04.3 LTS
#> system x86_64, linux-gnu
#> ui X11
#> language en
#> collate en_US.UTF-8
#> ctype en_US.UTF-8
#> tz UTC
#> date 2026-03-27
#> pandoc 3.8.2.1 @ /usr/bin/ (via rmarkdown)
#> quarto 1.7.32 @ /usr/local/bin/quarto
#>
#> ─ Packages ───────────────────────────────────────────────────────────────────────────────────────────────────────────
#> package * version date (UTC) lib source
#> abind 1.4-8 2024-09-12 [1] RSPM (R 4.5.0)
#> AnnotationDbi 1.72.0 2025-10-29 [1] Bioconductor 3.22 (R 4.5.2)
#> AnnotationHub 4.0.0 2025-10-29 [1] Bioconductor 3.22 (R 4.5.2)
#> attempt 0.3.1 2020-05-03 [1] RSPM (R 4.5.0)
#> backports 1.5.0 2024-05-23 [1] RSPM (R 4.5.0)
#> beachmat 2.26.0 2025-10-29 [1] Bioconductor 3.22 (R 4.5.2)
#> beeswarm 0.4.0 2021-06-01 [1] RSPM (R 4.5.0)
#> benchmarkme 1.0.8 2022-06-12 [1] RSPM (R 4.5.0)
#> benchmarkmeData 2.0.0 2026-01-19 [1] RSPM (R 4.5.0)
#> bibtex 0.5.2 2026-02-03 [1] RSPM (R 4.5.0)
#> Biobase * 2.70.0 2025-10-29 [1] Bioconductor 3.22 (R 4.5.2)
#> BiocFileCache 3.0.0 2025-10-29 [1] Bioconductor 3.22 (R 4.5.2)
#> BiocGenerics * 0.56.0 2025-10-29 [1] Bioconductor 3.22 (R 4.5.2)
#> BiocIO 1.20.0 2025-10-29 [1] Bioconductor 3.22 (R 4.5.2)
#> BiocManager 1.30.27 2025-11-14 [2] CRAN (R 4.5.2)
#> BiocNeighbors 2.4.0 2025-10-29 [1] Bioconductor 3.22 (R 4.5.2)
#> BiocParallel 1.44.0 2025-10-29 [1] Bioconductor 3.22 (R 4.5.2)
#> BiocSingular 1.26.1 2025-11-17 [1] Bioconductor 3.22 (R 4.5.2)
#> BiocStyle * 2.38.0 2025-10-29 [1] Bioconductor 3.22 (R 4.5.2)
#> BiocVersion 3.22.0 2025-10-07 [2] Bioconductor 3.22 (R 4.5.2)
#> Biostrings 2.78.0 2025-10-29 [1] Bioconductor 3.22 (R 4.5.2)
#> bit 4.6.0 2025-03-06 [1] RSPM (R 4.5.0)
#> bit64 4.6.0-1 2025-01-16 [1] RSPM (R 4.5.0)
#> bitops 1.0-9 2024-10-03 [1] RSPM (R 4.5.0)
#> blob 1.3.0 2026-01-14 [1] RSPM (R 4.5.0)
#> bookdown 0.46 2025-12-05 [1] RSPM (R 4.5.0)
#> bslib 0.10.0 2026-01-26 [2] RSPM (R 4.5.0)
#> cachem 1.1.0 2024-05-16 [2] RSPM (R 4.5.0)
#> cigarillo 1.0.0 2025-10-29 [1] Bioconductor 3.22 (R 4.5.2)
#> circlize 0.4.17 2025-12-08 [1] RSPM (R 4.5.0)
#> cli 3.6.5 2025-04-23 [2] RSPM (R 4.5.0)
#> clue 0.3-67 2026-02-18 [1] RSPM (R 4.5.0)
#> cluster 2.1.8.2 2026-02-05 [3] RSPM (R 4.5.0)
#> codetools 0.2-20 2024-03-31 [3] CRAN (R 4.5.2)
#> colorspace 2.1-2 2025-09-22 [1] RSPM (R 4.5.0)
#> ComplexHeatmap 2.26.1 2026-02-03 [1] Bioconductor 3.22 (R 4.5.2)
#> config 0.3.2 2023-08-30 [1] RSPM (R 4.5.0)
#> cowplot 1.2.0 2025-07-07 [1] RSPM (R 4.5.0)
#> crayon 1.5.3 2024-06-20 [2] RSPM (R 4.5.0)
#> curl 7.0.0 2025-08-19 [2] RSPM (R 4.5.0)
#> data.table 1.18.2.1 2026-01-27 [1] RSPM (R 4.5.0)
#> DBI 1.3.0 2026-02-25 [1] RSPM (R 4.5.0)
#> dbplyr 2.5.2 2026-02-13 [1] RSPM (R 4.5.0)
#> DelayedArray 0.36.0 2025-10-29 [1] Bioconductor 3.22 (R 4.5.2)
#> desc 1.4.3 2023-12-10 [2] RSPM (R 4.5.0)
#> digest 0.6.39 2025-11-19 [2] RSPM (R 4.5.0)
#> doParallel 1.0.17 2022-02-07 [1] RSPM (R 4.5.0)
#> dplyr 1.2.0 2026-02-03 [1] RSPM (R 4.5.0)
#> DT 0.34.0 2025-09-02 [1] RSPM (R 4.5.0)
#> edgeR 4.8.2 2025-12-25 [1] Bioconductor 3.22 (R 4.5.2)
#> evaluate 1.0.5 2025-08-27 [2] RSPM (R 4.5.0)
#> ExperimentHub 3.0.0 2025-10-29 [1] Bioconductor 3.22 (R 4.5.2)
#> farver 2.1.2 2024-05-13 [1] RSPM (R 4.5.0)
#> fastmap 1.2.0 2024-05-15 [2] RSPM (R 4.5.0)
#> filelock 1.0.3 2023-12-11 [1] RSPM (R 4.5.0)
#> foreach 1.5.2 2022-02-02 [1] RSPM (R 4.5.0)
#> fs 2.0.1 2026-03-24 [2] RSPM (R 4.5.0)
#> generics * 0.1.4 2025-05-09 [1] RSPM (R 4.5.0)
#> GenomicAlignments 1.46.0 2025-10-29 [1] Bioconductor 3.22 (R 4.5.2)
#> GenomicRanges * 1.62.1 2025-12-08 [1] Bioconductor 3.22 (R 4.5.2)
#> GetoptLong 1.1.0 2025-11-28 [1] RSPM (R 4.5.0)
#> ggbeeswarm 0.7.3 2025-11-29 [1] RSPM (R 4.5.0)
#> ggplot2 4.0.2 2026-02-03 [1] RSPM (R 4.5.0)
#> ggrepel 0.9.8 2026-03-17 [1] RSPM (R 4.5.0)
#> GlobalOptions 0.1.3 2025-11-28 [1] RSPM (R 4.5.0)
#> glue 1.8.0 2024-09-30 [2] RSPM (R 4.5.0)
#> golem 0.5.1 2024-08-27 [1] RSPM (R 4.5.0)
#> gridExtra 2.3 2017-09-09 [1] RSPM (R 4.5.0)
#> gtable 0.3.6 2024-10-25 [1] RSPM (R 4.5.0)
#> htmltools 0.5.9 2025-12-04 [2] RSPM (R 4.5.0)
#> htmlwidgets 1.6.4 2023-12-06 [2] RSPM (R 4.5.0)
#> httpuv 1.6.17 2026-03-18 [2] RSPM (R 4.5.0)
#> httr 1.4.8 2026-02-13 [1] RSPM (R 4.5.0)
#> httr2 1.2.2 2025-12-08 [2] RSPM (R 4.5.0)
#> IRanges * 2.44.0 2025-10-29 [1] Bioconductor 3.22 (R 4.5.2)
#> irlba 2.3.7 2026-01-30 [1] RSPM (R 4.5.0)
#> iterators 1.0.14 2022-02-05 [1] RSPM (R 4.5.0)
#> jquerylib 0.1.4 2021-04-26 [2] RSPM (R 4.5.0)
#> jsonlite 2.0.0 2025-03-27 [2] RSPM (R 4.5.0)
#> KEGGREST 1.50.0 2025-10-29 [1] Bioconductor 3.22 (R 4.5.2)
#> knitr 1.51 2025-12-20 [2] RSPM (R 4.5.0)
#> labeling 0.4.3 2023-08-29 [1] RSPM (R 4.5.0)
#> later 1.4.8 2026-03-05 [2] RSPM (R 4.5.0)
#> lattice 0.22-9 2026-02-09 [3] RSPM (R 4.5.0)
#> lazyeval 0.2.2 2019-03-15 [1] RSPM (R 4.5.0)
#> lifecycle 1.0.5 2026-01-08 [2] RSPM (R 4.5.0)
#> limma 3.66.0 2025-10-29 [1] Bioconductor 3.22 (R 4.5.2)
#> locfit 1.5-9.12 2025-03-05 [1] RSPM (R 4.5.0)
#> lubridate 1.9.5 2026-02-04 [1] RSPM (R 4.5.0)
#> magick 2.9.1 2026-02-28 [1] RSPM (R 4.5.0)
#> magrittr 2.0.4 2025-09-12 [2] RSPM (R 4.5.0)
#> Matrix 1.7-5 2026-03-21 [3] RSPM (R 4.5.0)
#> MatrixGenerics * 1.22.0 2025-10-29 [1] Bioconductor 3.22 (R 4.5.2)
#> matrixStats * 1.5.0 2025-01-07 [1] RSPM (R 4.5.0)
#> memoise 2.0.1 2021-11-26 [2] RSPM (R 4.5.0)
#> mime 0.13 2025-03-17 [2] RSPM (R 4.5.0)
#> otel 0.2.0 2025-08-29 [2] RSPM (R 4.5.0)
#> paletteer 1.7.0 2026-01-08 [1] RSPM (R 4.5.0)
#> pillar 1.11.1 2025-09-17 [2] RSPM (R 4.5.0)
#> pkgconfig 2.0.3 2019-09-22 [2] RSPM (R 4.5.0)
#> pkgdown 2.2.0 2025-11-06 [2] RSPM (R 4.5.0)
#> plotly 4.12.0 2026-01-24 [1] RSPM (R 4.5.0)
#> plyr 1.8.9 2023-10-02 [1] RSPM (R 4.5.0)
#> png 0.1-9 2026-03-15 [1] RSPM (R 4.5.0)
#> promises 1.5.0 2025-11-01 [2] RSPM (R 4.5.0)
#> purrr 1.2.1 2026-01-09 [2] RSPM (R 4.5.0)
#> R6 2.6.1 2025-02-15 [2] RSPM (R 4.5.0)
#> ragg 1.5.2 2026-03-23 [2] RSPM (R 4.5.0)
#> rappdirs 0.3.4 2026-01-17 [2] RSPM (R 4.5.0)
#> RColorBrewer 1.1-3 2022-04-03 [1] RSPM (R 4.5.0)
#> Rcpp 1.1.1 2026-01-10 [2] RSPM (R 4.5.0)
#> RCurl 1.98-1.18 2026-03-21 [1] RSPM (R 4.5.0)
#> RefManageR * 1.4.0 2022-09-30 [1] RSPM (R 4.5.0)
#> rematch2 2.1.2 2020-05-01 [1] RSPM (R 4.5.0)
#> restfulr 0.0.16 2025-06-27 [1] RSPM (R 4.5.2)
#> rjson 0.2.23 2024-09-16 [1] RSPM (R 4.5.0)
#> rlang 1.1.7 2026-01-09 [2] RSPM (R 4.5.0)
#> rmarkdown 2.30 2025-09-28 [2] RSPM (R 4.5.0)
#> Rsamtools 2.26.0 2025-10-29 [1] Bioconductor 3.22 (R 4.5.2)
#> RSQLite 2.4.6 2026-02-06 [1] RSPM (R 4.5.0)
#> rsvd 1.0.5 2021-04-16 [1] RSPM (R 4.5.0)
#> rtracklayer 1.70.1 2025-12-22 [1] Bioconductor 3.22 (R 4.5.2)
#> S4Arrays 1.10.1 2025-12-01 [1] Bioconductor 3.22 (R 4.5.2)
#> S4Vectors * 0.48.0 2025-10-29 [1] Bioconductor 3.22 (R 4.5.2)
#> S7 0.2.1 2025-11-14 [1] RSPM (R 4.5.0)
#> sass 0.4.10 2025-04-11 [2] RSPM (R 4.5.0)
#> ScaledMatrix 1.18.0 2025-10-29 [1] Bioconductor 3.22 (R 4.5.2)
#> scales 1.4.0 2025-04-24 [1] RSPM (R 4.5.0)
#> scater 1.38.1 2026-03-20 [1] Bioconductor 3.22 (R 4.5.2)
#> scuttle 1.20.0 2025-10-30 [1] Bioconductor 3.22 (R 4.5.2)
#> Seqinfo * 1.0.0 2025-10-29 [1] Bioconductor 3.22 (R 4.5.2)
#> sessioninfo * 1.2.3 2025-02-05 [2] RSPM (R 4.5.0)
#> shape 1.4.6.1 2024-02-23 [1] RSPM (R 4.5.0)
#> shiny 1.13.0 2026-02-20 [2] RSPM (R 4.5.0)
#> shinyWidgets 0.9.1 2026-03-09 [1] RSPM (R 4.5.0)
#> SingleCellExperiment * 1.32.0 2025-10-29 [1] Bioconductor 3.22 (R 4.5.2)
#> SparseArray 1.10.9 2026-03-06 [1] Bioconductor 3.22 (R 4.5.2)
#> SpatialExperiment * 1.20.0 2025-10-29 [1] Bioconductor 3.22 (R 4.5.2)
#> spatialLIBD * 1.23.2 2026-03-27 [1] Bioconductor
#> statmod 1.5.1 2025-10-09 [1] RSPM (R 4.5.0)
#> stringi 1.8.7 2025-03-27 [2] RSPM (R 4.5.0)
#> stringr 1.6.0 2025-11-04 [2] RSPM (R 4.5.0)
#> SummarizedExperiment * 1.40.0 2025-10-29 [1] Bioconductor 3.22 (R 4.5.2)
#> systemfonts 1.3.2 2026-03-05 [2] RSPM (R 4.5.0)
#> textshaping 1.0.5 2026-03-06 [2] RSPM (R 4.5.0)
#> tibble 3.3.1 2026-01-11 [2] RSPM (R 4.5.0)
#> tidyr 1.3.2 2025-12-19 [1] RSPM (R 4.5.0)
#> tidyselect 1.2.1 2024-03-11 [1] RSPM (R 4.5.0)
#> timechange 0.4.0 2026-01-29 [1] RSPM (R 4.5.0)
#> vctrs 0.7.2 2026-03-21 [2] RSPM (R 4.5.0)
#> vipor 0.4.7 2023-12-18 [1] RSPM (R 4.5.0)
#> viridis 0.6.5 2024-01-29 [1] RSPM (R 4.5.0)
#> viridisLite 0.4.3 2026-02-04 [1] RSPM (R 4.5.0)
#> withr 3.0.2 2024-10-28 [2] RSPM (R 4.5.0)
#> xfun 0.57 2026-03-20 [2] RSPM (R 4.5.0)
#> XML 3.99-0.23 2026-03-20 [1] RSPM (R 4.5.0)
#> xml2 1.5.2 2026-01-17 [2] RSPM (R 4.5.0)
#> xtable 1.8-8 2026-02-22 [2] RSPM (R 4.5.0)
#> XVector 0.50.0 2025-10-29 [1] Bioconductor 3.22 (R 4.5.2)
#> yaml 2.3.12 2025-12-10 [2] RSPM (R 4.5.0)
#>
#> [1] /__w/_temp/Library
#> [2] /usr/local/lib/R/site-library
#> [3] /usr/local/lib/R/library
#> * ── Packages attached to the search path.
#>
#> ──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────Bibliography
This vignette was generated using BiocStyle (Oleś, 2025), knitr (Xie, 2014) and rmarkdown (Allaire, Xie, Dervieux, McPherson, Luraschi, Ushey, Atkins, Wickham, Cheng, Chang, and Iannone, 2025) running behind the scenes.
Citations made with RefManageR (McLean, 2017).
[1] J. Allaire, Y. Xie, C. Dervieux, et al. rmarkdown: Dynamic Documents for R. R package version 2.30. 2025. URL: https://github.com/rstudio/rmarkdown.
[2] L. A. Huuki-Myers, A. Spangler, N. J. Eagles, et al. “A data-driven single-cell and spatial transcriptomic map of the human prefrontal cortex”. In: Science (2024). DOI: 10.1126/science.adh1938. URL: https://doi.org/10.1126/science.adh1938.
[3] K. R. Maynard, L. Collado-Torres, L. M. Weber, et al. “Transcriptome-scale spatial gene expression in the human dorsolateral prefrontal cortex”. In: Nature Neuroscience (2021). DOI: 10.1038/s41593-020-00787-0. URL: https://www.nature.com/articles/s41593-020-00787-0.
[4] M. W. McLean. “RefManageR: Import and Manage BibTeX and BibLaTeX References in R”. In: The Journal of Open Source Software (2017). DOI: 10.21105/joss.00338.
[5] A. Oleś. BiocStyle: Standard styles for vignettes and other Bioconductor documents. R package version 2.38.0. 2025. DOI: 10.18129/B9.bioc.BiocStyle. URL: https://bioconductor.org/packages/BiocStyle.
[6] M. N. Tran, K. R. Maynard, A. Spangler, et al. “Single-nucleus transcriptome analysis reveals cell-type-specific molecular signatures across reward circuitry in the human brain”. In: Neuron (2021). DOI: 10.1016/j.neuron.2021.09.001.
[7] Y. Xie. “knitr: A Comprehensive Tool for Reproducible Research in R”. In: Implementing Reproducible Computational Research. Ed. by V. Stodden, F. Leisch and R. D. Peng. ISBN 978-1466561595. Chapman and Hall/CRC, 2014.