Finding Marker Genes with DeconvoBuddies
Louise Huuki-Myers
Lieber Institute for Brain Development, Johns Hopkins Medical Campuslahuuki@gmail.com
31 March 2026
Source:vignettes/Marker_Finding.Rmd
Marker_Finding.RmdIntroduction
What are Marker Genes?
Cell type marker genes have cell type specific expression, that is high expression in the target cell type, and low expression in all other cell types. Sub-setting the genes considered in a cell type deconvolution analysis helps reduce noise and can improve the accuracy of a deconvolution method.
How can we select marker genes?
There are several approaches to select marker genes.
One popular method is “1 vs. All” differential expression (Lun et al., n.d.), where genes are tested for differential expression between the target cell type, and a combined group of all “other” cell types. Statistically significant differentially expressed genes (DEGs) can be selected as a set of marker genes, DEGs can be ranked by high log fold change.
However in some cases 1vAll can select genes with high expression in non-target cell types, especially in cell types related to the target cell types (such as Neuron sub-types), or when there is a smaller number of cells in the cell type and the signal is disguised within the other group.
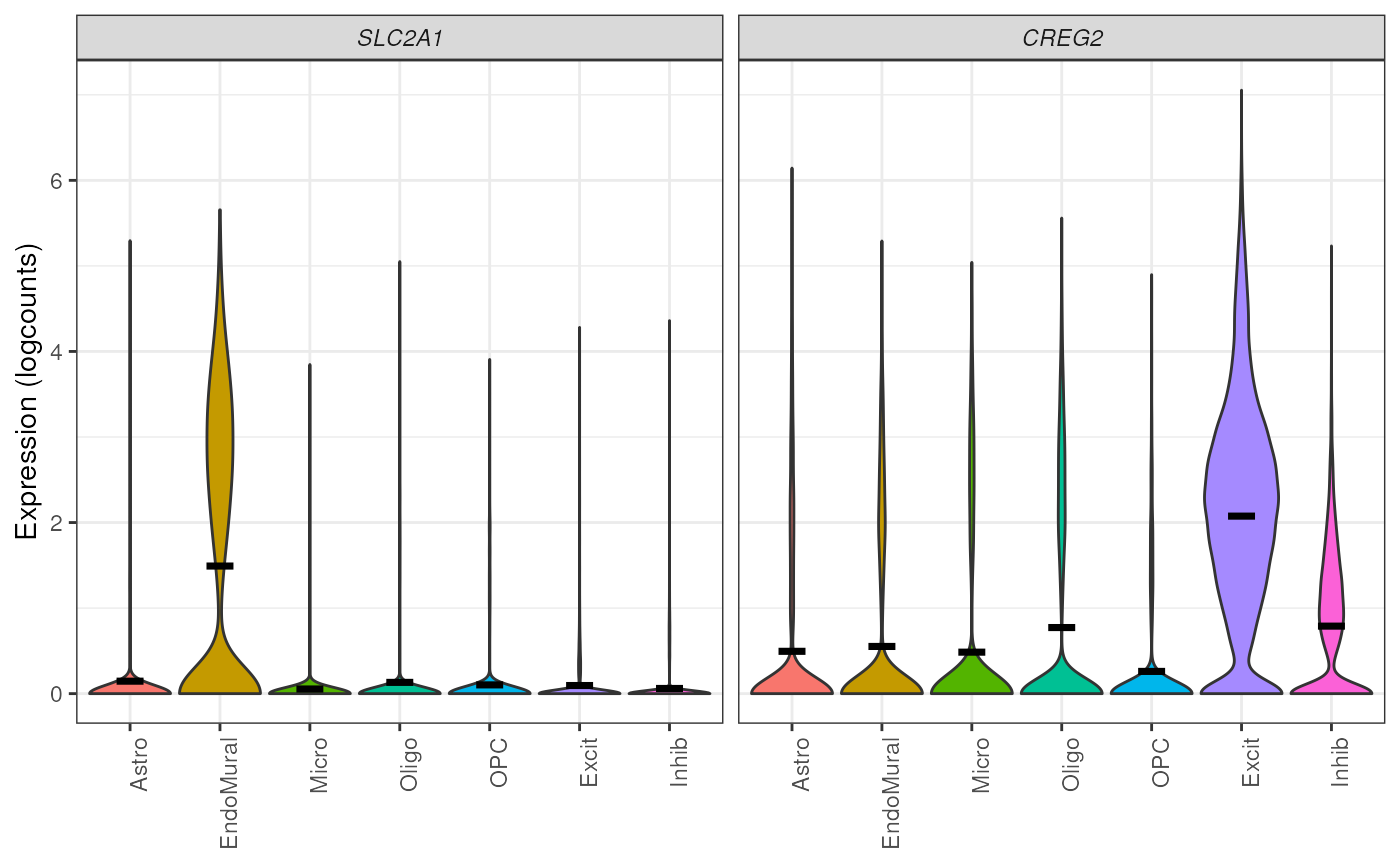
For example, in our snRNA-seq dataset from Human DLPFC (Huuki-Myers et al. 2024) selecting marker gene for the cell type Oligodendrocyte (Oligo), MBP has a high log fold change when testing by 1vALL (see illustration below). But, when the expression of MBP is observed by individual cell types there is also expression in the related cell types Microglia (Micro) and Oligodendrocyte precursor cells (OPC).
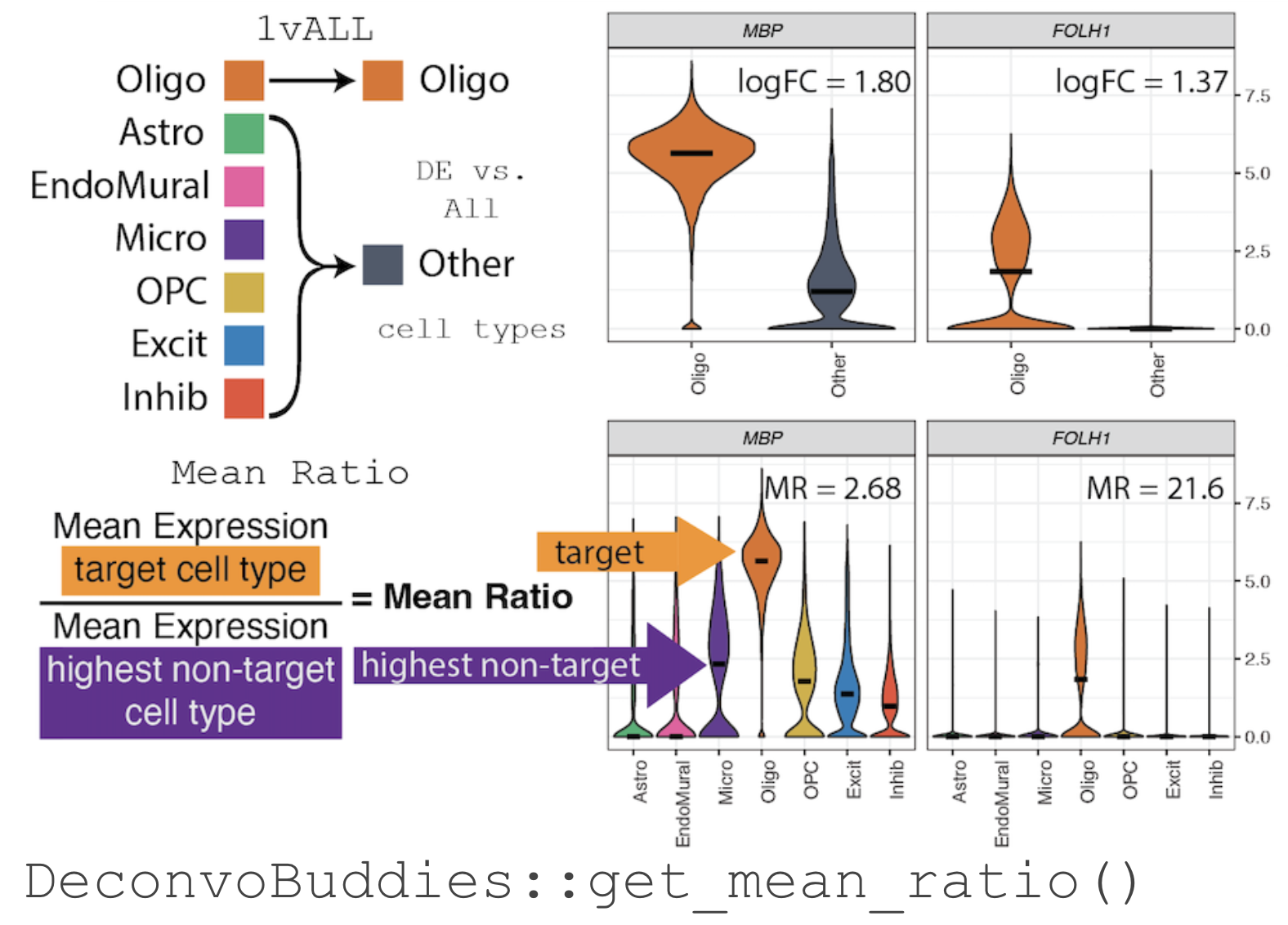
The Mean Ratio Method
To capture genes with more cell type specific expression and less
noise, we developed the Mean Ratio method. The
Mean Ratio method works by selecting genes with large
differences between gene expression in the target cell type and the
closest non-target cell type, by evaluating genes by their
MeanRatio metric.
We calculate the MeanRatio for a target cell type for
each gene by dividing the mean expression of the target cell by
the mean expression of the next highest non-target cell type.
Genes with the highest MeanRatio values are selected as
marker genes.
In the above example, Oligo is the target cell type.
Micro has the highest mean expression out of the other non-target (not
Oligo) cell types. The
MeanRatio = (mean expression Oligo) / (mean expression Micro),
for MBP MeanRatio = 2.68 for gene FOLH1
MeanRatio is much higher 21.6 showing FOLH1 is the better
marker gene (in contrast to ranking by 1vALL log FC). In the
violin plots you can see that expression of FOLH1 is much more
specific to Oligo than MBP, supporting the ranking by
MeanRatio.
We have implemented the Mean Ratio method
in this R package with the function get_mean_ratio(). This
vignette will cover our process for marker gene selection.
Goals of this Vignette
We will be demonstrating how to use DeconvoBuddies tools
when finding cell type marker genes in single cell RNA-seq data via the
MeanRatio method.
- Install and load required packages
- Download DLPFC snRNA-seq data
- Find MeanRatio marker genes with
DeconvoBuddies::get_mean_ratio() - Find 1vALL marker genes with
DeconvoBuddies::findMarkers_1vALL() - Compare marker gene selection
- Visualize marker genes expression with
DeconcoBuddies::plot_gene_express()and related functions
1. Install and load required packages
R is an open-source statistical environment which can be
easily modified to enhance its functionality via packages. DeconvoBuddies
is a R package available via the Bioconductor repository for packages.
R can be installed on any operating system from CRAN after which you can install
DeconvoBuddies
by using the following commands in your R session:
Install DeconvoBuddies
if (!requireNamespace("BiocManager", quietly = TRUE)) {
install.packages("BiocManager")
}
BiocManager::install("DeconvoBuddies")
## Check that you have a valid Bioconductor installation
BiocManager::valid()Load Other Packages
Let’s load the packages will use in this vignette.
## Packages for different types of RNA-seq data structures in R
library("SingleCellExperiment")
## For downloading data
library("spatialLIBD")
## Other helper packages for this vignette
library("dplyr")
library("ggplot2")
## Our main package
library("DeconvoBuddies")2. Download DLPFC snRNA-seq data.
Here we will download single nucleus RNA-seq data from the Human
DLPFC with 77k nuclei x 36k genes (Huuki-Myers et
al. 2024). This data is stored in a
SingleCellExperiment object. The nuclei in this dataset are
labeled by cell types at a few resolutions, we will focus on the “broad”
resolution that contains seven cell types.
## Use spatialLIBD to fetch the snRNA-seq dataset
sce_path_zip <- fetch_deconvo_data("sce")
#> 2026-03-31 18:38:30.044724 loading file /github/home/.cache/R/BiocFileCache/47f65b593efa_sce_DLPFC_annotated.zip%3Fdl%3D1
## unzip and load the data
sce_path <- unzip(sce_path_zip, exdir = tempdir())
sce <- HDF5Array::loadHDF5SummarizedExperiment(
file.path(tempdir(), "sce_DLPFC_annotated")
)
# lobstr::obj_size(sce)
# 172.28 MB
## exclude Ambiguous cell type
sce <- sce[, sce$cellType_broad_hc != "Ambiguous"]
sce$cellType_broad_hc <- droplevels(sce$cellType_broad_hc)
## Check the broad cell type distribution
table(sce$cellType_broad_hc)
#>
#> Astro EndoMural Micro Oligo OPC Excit Inhib
#> 3979 2157 1601 10894 1940 24809 11067
## We're going to subset to the first 5k genes to save memory
## In a real application you'll want to use the full dataset
sce <- sce[seq_len(5000), ]
## check the final dimensions of the dataset
dim(sce)
#> [1] 5000 564473. Find MeanRatio marker genes
To find Mean Ratio marker genes for the data in
sce we’ll use the function
DeconvoBuddies::get_mean_ratio(), this function takes a
SingleCellExperiment object sce the name of
the column in the colData(sce) that contains the cell type
annotations of interest (here we’ll use cellType_broad_hc),
and optionally you can also supply additional column names from the
rowData(sce) to add the gene_name and/or
gene_ensembl information to the table output of
get_mean_ratio. While the speedup is notably worse than
linear with the number of cores provided, computation can nevertheless
be parallelized with a BPPARAM argument from
BiocParallel to save some time.
# calculate the Mean Ratio of genes for each cell type in sce
marker_stats_MeanRatio <- get_mean_ratio(
sce = sce, # sce is the SingleCellExperiment with our data
assay_name = "logcounts", ## assay to use, we recommend logcounts [default]
cellType_col = "cellType_broad_hc", # column in colData with cell type info
gene_ensembl = "gene_id", # column in rowData with ensembl gene ids
gene_name = "gene_name" # column in rowData with gene names/symbols
)
#> Warning in get_mean_ratio(sce = sce, assay_name = "logcounts", cellType_col =
#> "cellType_broad_hc", : Assay is a DelayedMatrix. For considerably faster marker
#> finding, consider bringing in memory as a dgCMatrix.The function get_mean_ratio() returns a
tibble with the following columns:
-
geneis the name of the gene (from rownames(sce)). -
cellType.targetis the cell type we’re finding marker genes for. -
mean.targetis the mean expression ofgeneforcellType.target. -
cellType.2ndis the second highest non-target cell type. -
mean.2ndis the mean expression ofgeneforcellType.2nd. -
MeanRatiois the ratio ofmean.target/mean.2nd. -
MeanRatio.rankis the rank ofMeanRatiofor the cell type. -
MeanRatio.annois an annotation of theMeanRatiocalculation helpful for plotting. -
gene_ensembl&gene_nameoptional cols fromrowData(sce)specified by the user to add gene information
## Explore the tibble output
marker_stats_MeanRatio
#> # A tibble: 1,721 × 10
#> gene cellType.target mean.target cellType.2nd mean.2nd MeanRatio
#> <chr> <fct> <dbl> <fct> <dbl> <dbl>
#> 1 LYPD6B Inhib 1.20 Excit 0.0967 12.4
#> 2 GREM2 Inhib 1.20 Excit 0.271 4.44
#> 3 IGSF3 Inhib 0.899 Excit 0.241 3.72
#> 4 GALNT14 Inhib 1.86 Excit 0.503 3.69
#> 5 LYPD6 Inhib 1.09 Astro 0.435 2.51
#> 6 SLC35D1 Inhib 0.781 OPC 0.375 2.08
#> 7 FLVCR1 Inhib 0.576 Excit 0.336 1.72
#> 8 RAVER2 Inhib 1.09 OPC 0.651 1.68
#> 9 ARHGEF11 Inhib 1.81 Excit 1.10 1.64
#> 10 VAV3 Inhib 1.68 Astro 1.03 1.63
#> # ℹ 1,711 more rows
#> # ℹ 4 more variables: MeanRatio.rank <int>, MeanRatio.anno <chr>,
#> # gene_ensembl <chr>, gene_name <chr>
## genes with the highest MeanRatio are the best marker genes for each cell type
marker_stats_MeanRatio |>
filter(MeanRatio.rank == 1)
#> # A tibble: 7 × 10
#> gene cellType.target mean.target cellType.2nd mean.2nd MeanRatio
#> <chr> <fct> <dbl> <fct> <dbl> <dbl>
#> 1 LYPD6B Inhib 1.20 Excit 0.0967 12.4
#> 2 AC012494.1 Oligo 2.37 OPC 0.147 16.1
#> 3 MIR3681HG OPC 1.58 Excit 0.205 7.69
#> 4 AC011995.2 Excit 1.01 Inhib 0.135 7.51
#> 5 PRDM16 Astro 1.97 EndoMural 0.142 13.9
#> 6 SLC2A1 EndoMural 1.49 Astro 0.146 10.2
#> 7 LINC01141 Micro 1.57 Excit 0.0640 24.5
#> # ℹ 4 more variables: MeanRatio.rank <int>, MeanRatio.anno <chr>,
#> # gene_ensembl <chr>, gene_name <chr>4. Find 1vALL marker genes
To further explore cell type marker genes it can be helpful to also
calculate the 1vALL stats for the dataset. To help with this we have
included the function DeconvoBuddies::findMarkers_1vALL(),
which is a wrapper for scran::findMarkers() that iterates
through cell types and creates an table output in a compatible with the
output DeconvoBuddies::get_mean_ratio().
Similarity to get_mean_ratio this function requires the
sce object, cellType_col to define cell types,
and assay_name. But findMarkers_1vALL() also
takes a model (mod) to use as design in
scran::findMarkers(), in this example we will control for
donor which is stored as BrNum.
Note this function can by default take a bit of time to run. However,
the computation can be parallelized by cell type with a nearly linear
speedup with the number of provided cores, by providing a
BPPARAM argument as supported through
BiocParallel. We have saved the output as
data("marker_stats_1vAll") to speed-up the runtime of this
vignette.
## Run 1vALL DE to find markers for each cell type - takes 5min+
# marker_stats_1vAll <- findMarkers_1vAll(
# sce = sce, # sce is the SingleCellExperiment with our data
# assay_name = "counts",
# cellType_col = "cellType_broad_hc", # column in colData with cell type info
# mod = "~BrNum" # Control for donor stored in "BrNum" with mod
# raw_logFC = TRUE # also retain raw logFC in addition to standardized
# )
## load 1vAll data to save time, data is equivalent to the above code
data("marker_stats_1vAll")The function findMarkers_1vALL() returns a
tibble with the following columns:
-
geneis the name of the gene (from rownames(sce)). -
std.logFCthe standard logFC -
log.p.valuethe log of the p-value of the DE test -
log.FDRthe log of the False Discovery Rate adjusted p.value -
logFCthe log fold change from the DE test, added whenraw_logFC=TRUE -
cellType.targetthe cell type we’re finding marker genes for -
std.logFC.rankthe rank ofstd.logFCfor each cell type -
std.logFC.annois an annotation of thestd.logFCvalue helpful for plotting.
## Explore the tibble output
marker_stats_1vAll
#> # A tibble: 35,000 × 8
#> # Groups: cellType.target [7]
#> gene logFC log.p.value log.FDR std.logFC cellType.target std.logFC.rank
#> <chr> <dbl> <dbl> <dbl> <dbl> <fct> <int>
#> 1 SILC1 2.77 -6747. -6739. 1.42 Inhib 1
#> 2 LYPD6B 2.48 -6338. -6330. 1.37 Inhib 2
#> 3 LYPD6 2.18 -6147. -6140. 1.35 Inhib 3
#> 4 ALK 4.56 -5707. -5700. 1.30 Inhib 4
#> 5 WLS 3.26 -5111. -5104. 1.22 Inhib 5
#> 6 PLD5 5.85 -4711. -4704. 1.17 Inhib 6
#> 7 KIRREL1 1.04 -4539. -4532. 1.14 Inhib 7
#> 8 TRIM67 0.622 -4326. -4319. 1.11 Inhib 8
#> 9 GREM2 2.11 -4048. -4042. 1.07 Inhib 9
#> 10 IGSF3 1.27 -3783. -3777. 1.04 Inhib 10
#> # ℹ 34,990 more rows
#> # ℹ 1 more variable: std.logFC.anno <chr>
## genes with the highest MeanRatio are the best marker genes for each cell type
marker_stats_1vAll |>
filter(std.logFC.rank == 1)
#> # A tibble: 7 × 8
#> # Groups: cellType.target [7]
#> gene logFC log.p.value log.FDR std.logFC cellType.target std.logFC.rank
#> <chr> <dbl> <dbl> <dbl> <dbl> <fct> <int>
#> 1 SILC1 2.77 -6747. -6739. 1.42 Inhib 1
#> 2 RNF220 10.7 -8373. -8365. 1.52 Oligo 1
#> 3 BX284613 7.42 -12763. -12754. 4.20 OPC 1
#> 4 KIAA1211L 7.89 -8371. -8362. 1.23 Excit 1
#> 5 PRDM16 1.90 -8853. -8844. 2.38 Astro 1
#> 6 EPAS1 6.50 -9480. -9471. 3.31 EndoMural 1
#> 7 CSF3R 0.808 -9670. -9661. 3.86 Micro 1
#> # ℹ 1 more variable: std.logFC.anno <chr>As this is a differential expression test, you can create volcano plots to explore the outputs. 🌋
Note that with the default option “up” for direction only
up-regulated genes are considered marker candidates, so all genes with
logFC<1 will have a p.value=0. As a results these plots will only
have the right half of the volcano shape. If you’d like all p-values set
findMarkers_1vALL(direction="any").
# Create volcano plots of DE stats from 1vALL
marker_stats_1vAll |>
ggplot(aes(logFC, -log.p.value)) +
geom_point() +
facet_wrap(~cellType.target) +
geom_vline(xintercept = c(1, -1), linetype = "dashed", color = "red")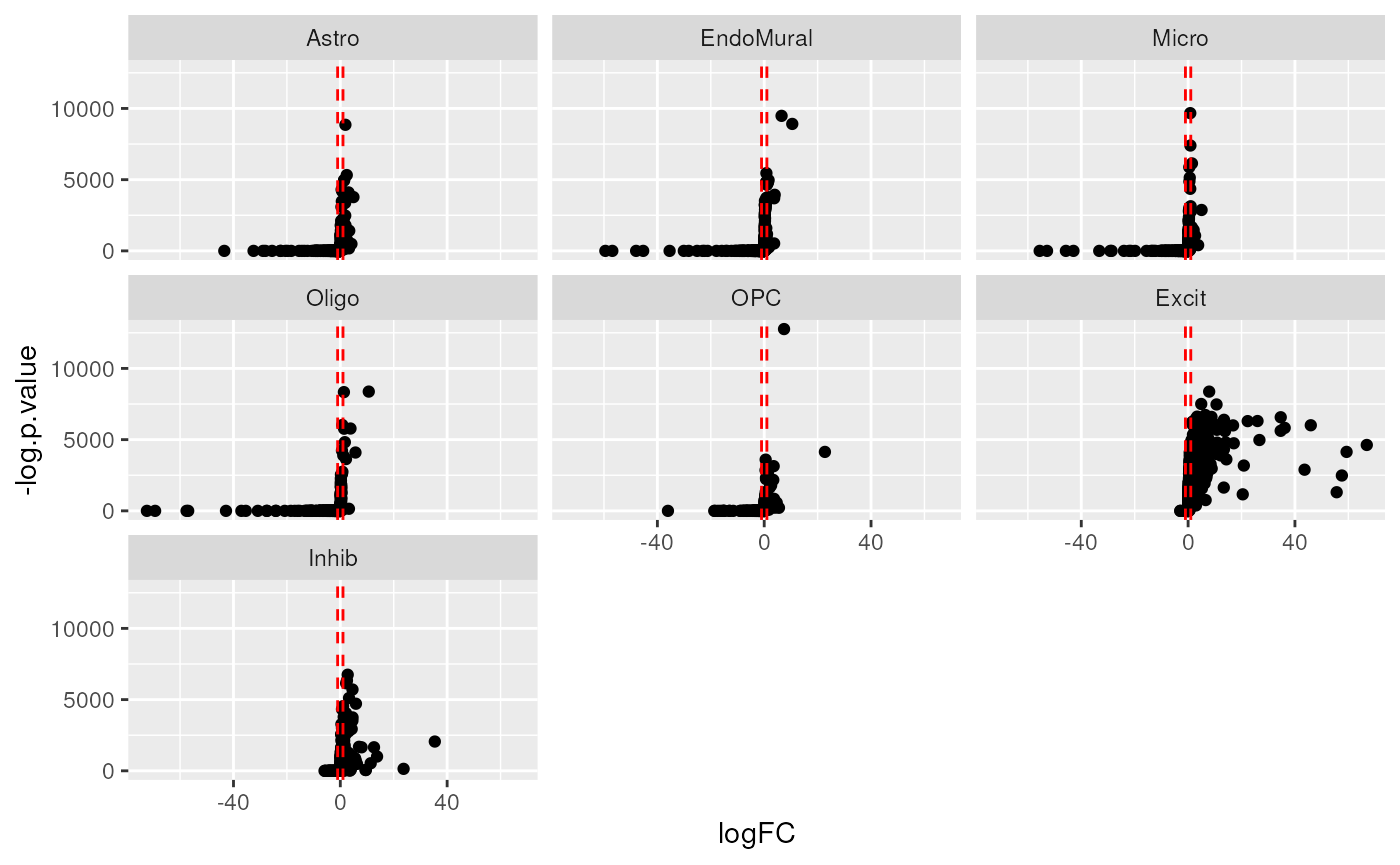
5. Compare Marker Gene Selection
Let’s join the two marker_stats tables together to
compare the findings of the two methods.
Note as we are using a subset of data for this example, for some genes there is not enough data to test and 1vALL will have some missing results.
## join the two marker_stats tables
marker_stats <- marker_stats_MeanRatio |>
left_join(marker_stats_1vAll, by = join_by(gene, cellType.target))
## Check stats for our top genes
marker_stats |>
filter(MeanRatio.rank == 1) |>
select(gene, cellType.target, MeanRatio, MeanRatio.rank, std.logFC, std.logFC.rank)
#> # A tibble: 7 × 6
#> gene cellType.target MeanRatio MeanRatio.rank std.logFC std.logFC.rank
#> <chr> <fct> <dbl> <int> <dbl> <int>
#> 1 LYPD6B Inhib 12.4 1 1.37 2
#> 2 AC012494.1 Oligo 16.1 1 NA NA
#> 3 MIR3681HG OPC 7.69 1 1.42 11
#> 4 AC011995.2 Excit 7.51 1 NA NA
#> 5 PRDM16 Astro 13.9 1 2.38 1
#> 6 SLC2A1 EndoMural 10.2 1 2.30 4
#> 7 LINC01141 Micro 24.5 1 2.07 8Hockey Stick Plots
Plotting the values of Mean Ratio vs. standard log fold change (from
1vAll) we create what we call “hockey stick plots” 🏒. These plots help
visualize the distribution of MeanRatio and standard
logFC values.
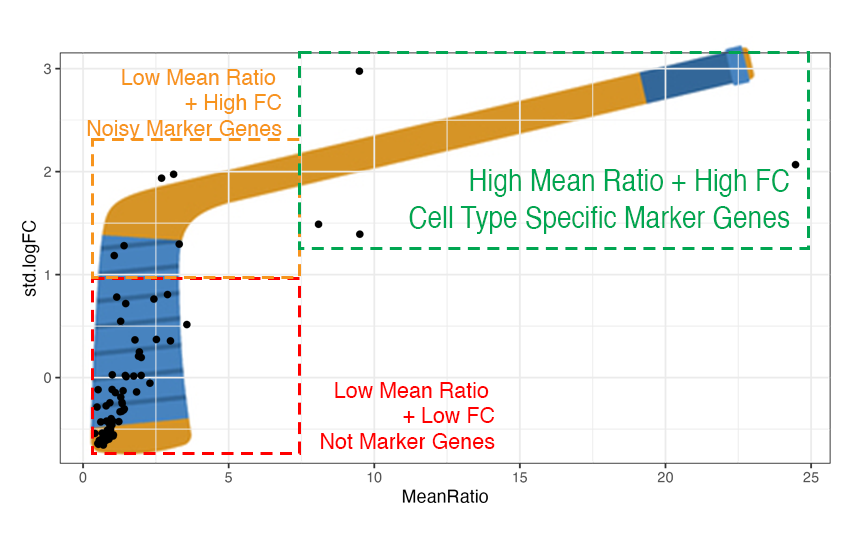
Typically for a cell type see most genes have low Mean Ratio and low fold change, these genes are not marker genes (red box in illustration above on the bottom left side).
Genes with higher fold change from 1vALL are better marker gene candidates, but most have low MeanRatio values indicating that one or more non-target cell types have high expression for that gene, causing noise (orange box on the top left side).
Genes with high MeanRatio typically also have high 1vALL standard fold changes, these are cell type specific marker genes we are selecting for (green box on the top right side).
# create hockey stick plots to compare MeanRatio and standard logFC values.
marker_stats |>
ggplot(aes(MeanRatio, std.logFC)) +
geom_point() +
facet_wrap(~cellType.target)
#> Warning: Removed 29 rows containing missing values or values outside the scale range
#> (`geom_point()`).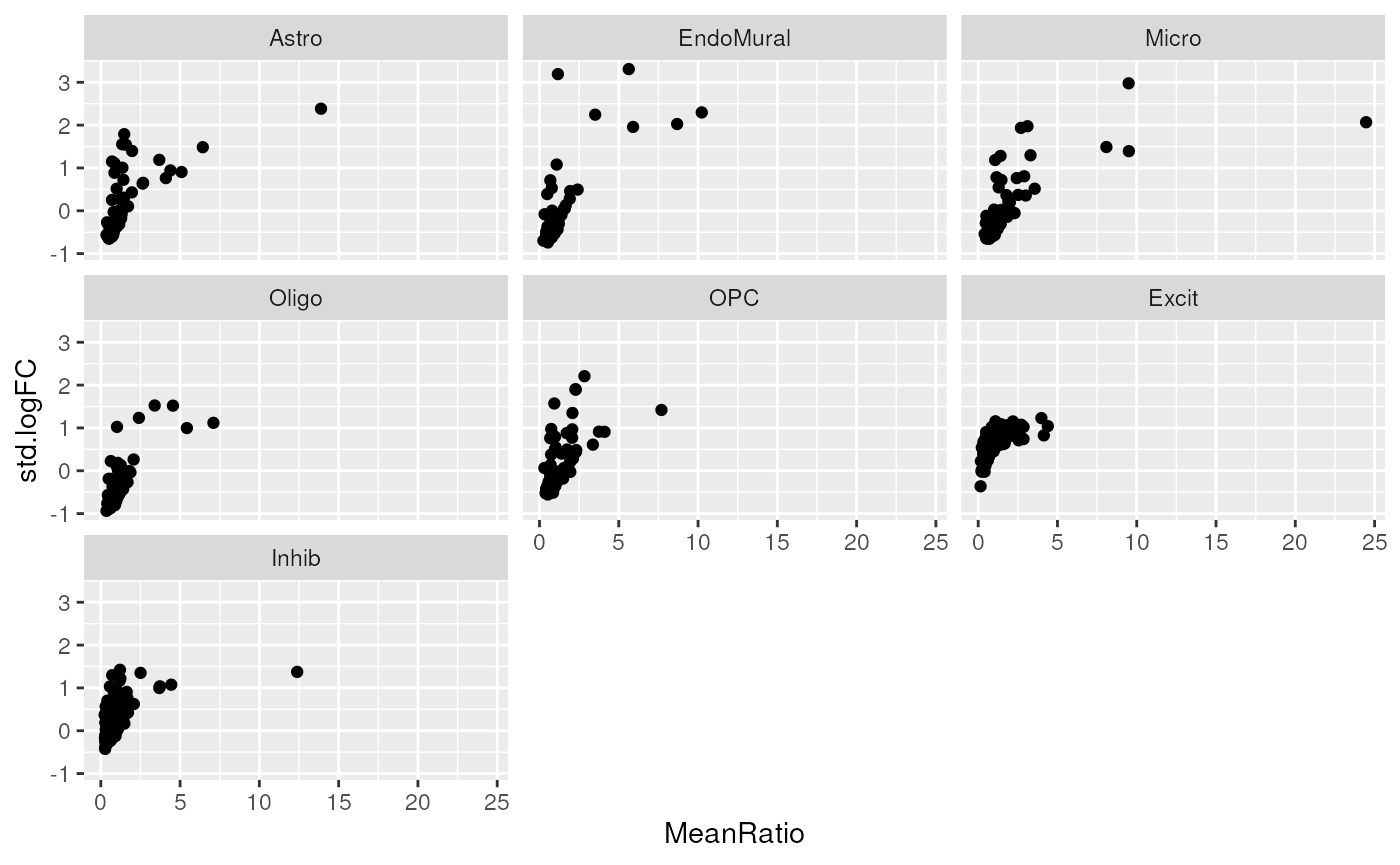
We can see a “hockey stick” shape in most of the cell types, with a
few marker genes with high values for both logFC and
MeanRatio.
6. Visualize Marker Genes Expression
An important step for ensuring you have selected high quality marker
genes is to visualize their expression over the cell types in the
dataset. DeconvoBuddies has several functions to help
quickly plot gene expression at a few levels:
plot_gene_express() plots the expression of one or more
genes as a violin plot.
## plot expression of two genes from a list
plot_gene_express(
sce = sce,
category = "cellType_broad_hc",
genes = c("SLC2A1", "CREG2")
)
plot_marker_express() plots the top n marker genes for a
specified cell type based on the values from marker_stats.
Annotations for the details of the MeanRatio value +
calculation are added to each panel.
# plot the top 10 MeanRatio genes for Excit
plot_marker_express(
sce = sce,
stats = marker_stats,
cell_type = "Excit",
n_genes = 10,
cellType_col = "cellType_broad_hc"
)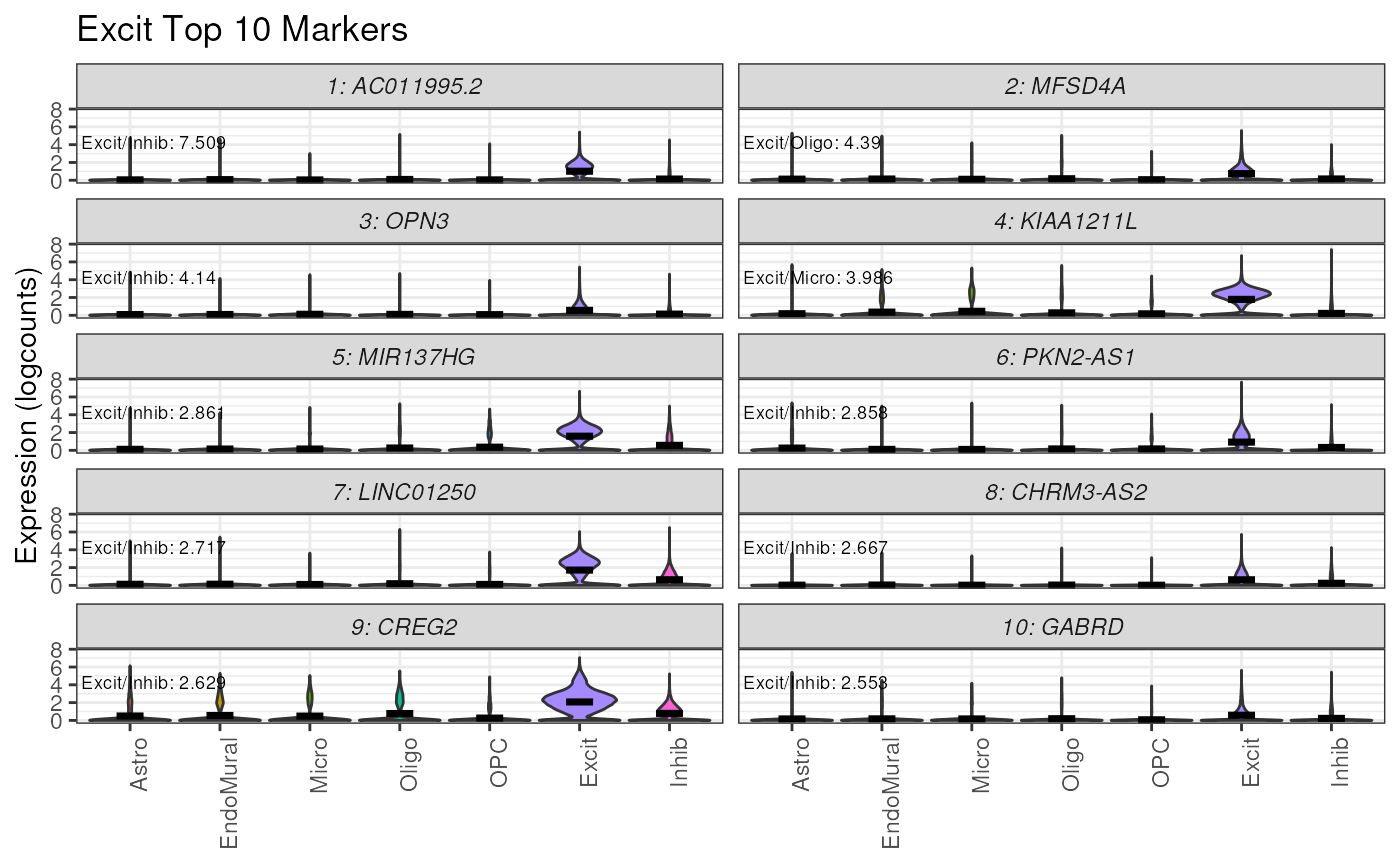
In these violin plots we can see these genes have high expression in the target cell type Excit , and mostly low expression nuclei in the other cell types, sometimes even no expression.
This function defaults to selecting genes by the MeanRatio stats, but can also be used to plot the 1vAll genes.
# plot the top 10 1vAll genes for Excit
plot_marker_express(
sce = sce,
stats = marker_stats,
cell_type = "Excit",
n_genes = 10,
rank_col = "std.logFC.rank", ## use logFC cols from 1vALL
anno_col = "std.logFC.anno",
cellType_col = "cellType_broad_hc"
)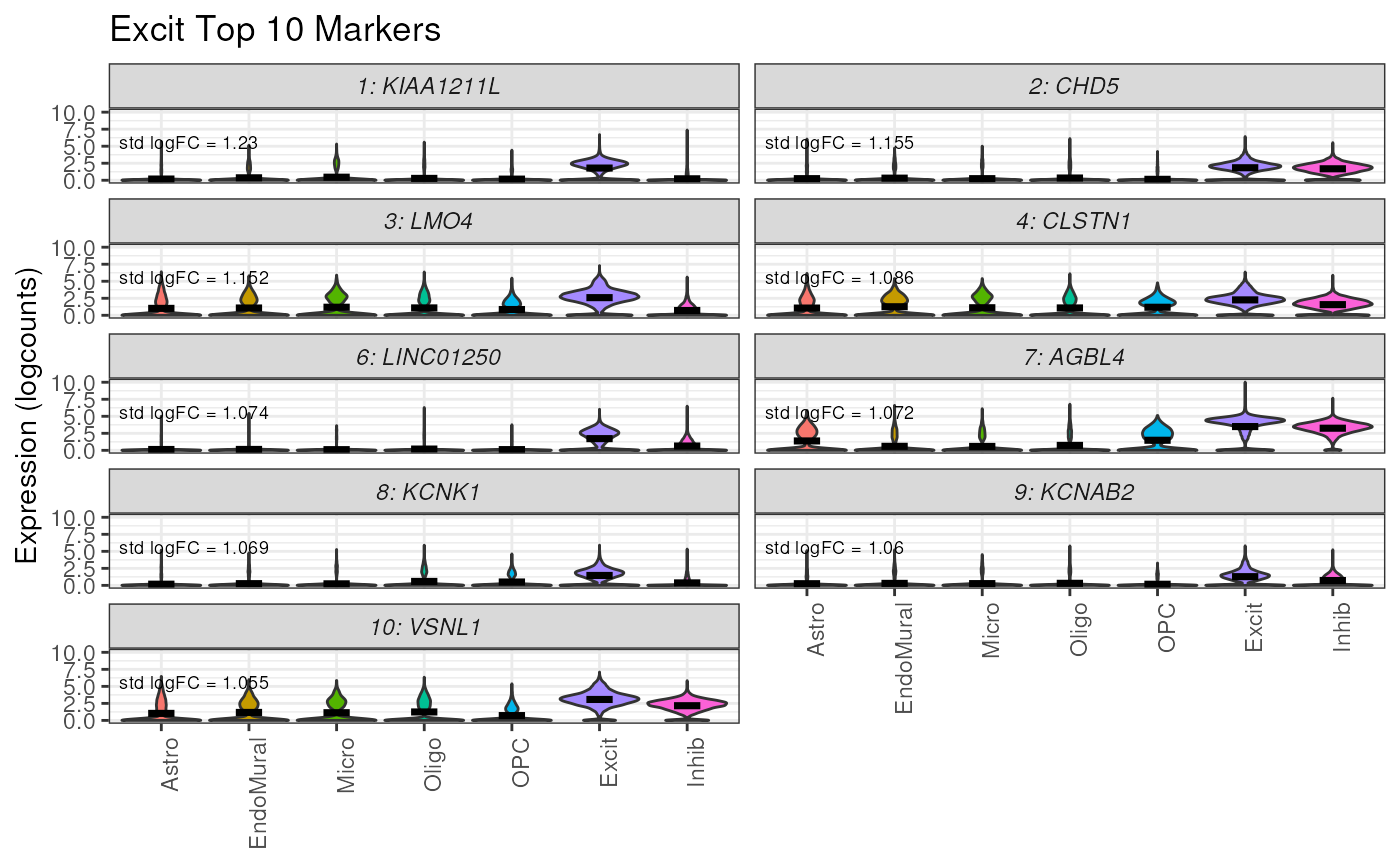
We can see in the top 1vALL genes there is some expression of these genes in Inhib nuclei in addition to the target cell type Excit.
plot_marker_express_ALL() plots the top marker genes for
all cell types. This is a quick and easy way to look at the the top
markers in your dataset, which is an important step and can help
identify genes with multimodal distributions that may confound the
MeanRatio method.
# plot the top 10 1vAll genes for all cell types
print(plot_marker_express_ALL(
sce = sce,
stats = marker_stats,
n_genes = 10,
cellType_col = "cellType_broad_hc"
))The violin plots can also be directly printed to a PDF file using the
built in argument
plot_marker_express_ALL(pdf = "my_marker_genes.pdf") for
portability and easy sharing.
Summary
In this vignette we covered the importance of finding marker genes,
and introduced our method for finding cell type specific genes
MeanRatio. We covered how to find and compare
MeanRatio marker genes with get_mean_ratio(), and
1vALL marker genes with findMarkers_1vALL(). And
finally, how to visualize the expression of these marker genes with
plot_marker_express() and related functions.
Next Steps
For an example of how to use these marker genes in a deconvolution workflow, check out Vignette: Deconvolution Benchmark in Human DLPFC.
We hope this vignette and DeconvoBuddies helps you with your research goals! Thanks for reading 😁
Reproducibility
The DeconvoBuddies package (Huuki-Myers, Maynard, Hicks, Zandi, Kleinman, Hyde, Goes, and Collado-Torres, 2026) was made possible thanks to:
- R (R Core Team, 2026)
- BiocStyle (Oleś, 2025)
- knitr (Xie, 2025)
- RefManageR (McLean, 2017)
- rmarkdown (Allaire, Xie, Dervieux, McPherson, Luraschi, Ushey, Atkins, Wickham, Cheng, Chang, and Iannone, 2026)
- sessioninfo (Wickham, Chang, Flight, Müller, and Hester, 2025)
- testthat (Wickham, 2011)
This package was developed using biocthis.
R session information.
#> ─ Session info ───────────────────────────────────────────────────────────────────────────────────────────────────────
#> setting value
#> version R Under development (unstable) (2026-03-28 r89738)
#> os Ubuntu 24.04.4 LTS
#> system x86_64, linux-gnu
#> ui X11
#> language en
#> collate en_US.UTF-8
#> ctype en_US.UTF-8
#> tz UTC
#> date 2026-03-31
#> pandoc 3.9.0.2 @ /usr/bin/ (via rmarkdown)
#> quarto 1.8.25 @ /usr/local/bin/quarto
#>
#> ─ Packages ───────────────────────────────────────────────────────────────────────────────────────────────────────────
#> package * version date (UTC) lib source
#> abind 1.4-8 2024-09-12 [1] CRAN (R 4.6.0)
#> AnnotationDbi 1.73.0 2025-10-31 [1] Bioconductor 3.23 (R 4.6.0)
#> AnnotationHub 4.1.0 2025-10-31 [1] Bioconductor 3.23 (R 4.6.0)
#> attempt 0.3.1 2020-05-03 [1] CRAN (R 4.6.0)
#> backports 1.5.0 2024-05-23 [1] CRAN (R 4.6.0)
#> beachmat 2.27.3 2026-02-27 [1] Bioconductor 3.23 (R 4.7.0)
#> beeswarm 0.4.0 2021-06-01 [1] CRAN (R 4.6.0)
#> benchmarkme 1.0.8 2022-06-12 [1] CRAN (R 4.6.0)
#> benchmarkmeData 2.0.0 2026-01-19 [1] CRAN (R 4.6.0)
#> bibtex 0.5.2 2026-02-03 [1] CRAN (R 4.6.0)
#> Biobase * 2.71.0 2025-10-30 [1] Bioconductor 3.23 (R 4.6.0)
#> BiocFileCache 3.1.0 2025-10-30 [1] Bioconductor 3.23 (R 4.6.0)
#> BiocGenerics * 0.57.0 2025-10-30 [1] Bioconductor 3.23 (R 4.6.0)
#> BiocIO 1.21.0 2025-10-30 [1] Bioconductor 3.23 (R 4.6.0)
#> BiocManager 1.30.27 2025-11-14 [2] CRAN (R 4.7.0)
#> BiocNeighbors 2.5.4 2026-02-12 [1] Bioconductor 3.23 (R 4.7.0)
#> BiocParallel 1.45.0 2025-10-30 [1] Bioconductor 3.23 (R 4.6.0)
#> BiocSingular 1.27.1 2025-11-17 [1] Bioconductor 3.23 (R 4.6.0)
#> BiocStyle * 2.39.0 2025-10-30 [1] Bioconductor 3.23 (R 4.6.0)
#> BiocVersion 3.23.1 2025-10-30 [2] Bioconductor 3.23 (R 4.7.0)
#> Biostrings 2.79.5 2026-03-06 [1] Bioconductor 3.23 (R 4.7.0)
#> bit 4.6.0 2025-03-06 [1] CRAN (R 4.6.0)
#> bit64 4.6.0-1 2025-01-16 [1] CRAN (R 4.6.0)
#> bitops 1.0-9 2024-10-03 [1] CRAN (R 4.6.0)
#> blob 1.3.0 2026-01-14 [1] CRAN (R 4.6.0)
#> bluster 1.21.1 2026-03-05 [1] Bioconductor 3.23 (R 4.7.0)
#> bookdown 0.46 2025-12-05 [1] CRAN (R 4.6.0)
#> bslib 0.10.0 2026-01-26 [2] CRAN (R 4.7.0)
#> cachem 1.1.0 2024-05-16 [2] CRAN (R 4.7.0)
#> cigarillo 1.1.0 2025-10-31 [1] Bioconductor 3.23 (R 4.6.0)
#> circlize 0.4.17 2025-12-08 [1] CRAN (R 4.6.0)
#> cli 3.6.5 2025-04-23 [2] CRAN (R 4.7.0)
#> clue 0.3-68 2026-03-26 [1] CRAN (R 4.7.0)
#> cluster 2.1.8.2 2026-02-05 [3] CRAN (R 4.7.0)
#> codetools 0.2-20 2024-03-31 [3] CRAN (R 4.7.0)
#> colorspace 2.1-2 2025-09-22 [1] CRAN (R 4.6.0)
#> ComplexHeatmap 2.27.1 2026-01-30 [1] Bioconductor 3.23 (R 4.6.0)
#> config 0.3.2 2023-08-30 [1] CRAN (R 4.6.0)
#> cowplot 1.2.0 2025-07-07 [1] CRAN (R 4.6.0)
#> crayon 1.5.3 2024-06-20 [2] CRAN (R 4.7.0)
#> curl 7.0.0 2025-08-19 [2] CRAN (R 4.7.0)
#> data.table 1.18.2.1 2026-01-27 [1] CRAN (R 4.6.0)
#> DBI 1.3.0 2026-02-25 [1] CRAN (R 4.7.0)
#> dbplyr 2.5.2 2026-02-13 [1] CRAN (R 4.7.0)
#> DeconvoBuddies * 1.3.2 2026-03-31 [1] Bioconductor
#> DelayedArray 0.37.0 2025-10-31 [1] Bioconductor 3.23 (R 4.6.0)
#> DelayedMatrixStats 1.33.0 2025-10-31 [1] Bioconductor 3.23 (R 4.6.0)
#> desc 1.4.3 2023-12-10 [2] CRAN (R 4.7.0)
#> digest 0.6.39 2025-11-19 [2] CRAN (R 4.7.0)
#> doParallel 1.0.17 2022-02-07 [1] CRAN (R 4.6.0)
#> dplyr * 1.2.0 2026-02-03 [1] CRAN (R 4.6.0)
#> dqrng 0.4.1 2024-05-28 [1] CRAN (R 4.6.0)
#> DT 0.34.0 2025-09-02 [1] CRAN (R 4.6.0)
#> edgeR 4.9.4 2026-03-02 [1] Bioconductor 3.23 (R 4.7.0)
#> evaluate 1.0.5 2025-08-27 [2] CRAN (R 4.7.0)
#> ExperimentHub 3.1.0 2025-10-31 [1] Bioconductor 3.23 (R 4.6.0)
#> farver 2.1.2 2024-05-13 [1] CRAN (R 4.6.0)
#> fastmap 1.2.0 2024-05-15 [2] CRAN (R 4.7.0)
#> filelock 1.0.3 2023-12-11 [1] CRAN (R 4.6.0)
#> foreach 1.5.2 2022-02-02 [1] CRAN (R 4.6.0)
#> fs 2.0.1 2026-03-24 [2] CRAN (R 4.7.0)
#> generics * 0.1.4 2025-05-09 [1] CRAN (R 4.6.0)
#> GenomicAlignments 1.47.0 2025-10-31 [1] Bioconductor 3.23 (R 4.6.0)
#> GenomicRanges * 1.63.1 2025-12-08 [1] Bioconductor 3.23 (R 4.6.0)
#> GetoptLong 1.1.0 2025-11-28 [1] CRAN (R 4.6.0)
#> ggbeeswarm 0.7.3 2025-11-29 [1] CRAN (R 4.6.0)
#> ggplot2 * 4.0.2 2026-02-03 [1] CRAN (R 4.6.0)
#> ggrepel 0.9.8 2026-03-17 [1] CRAN (R 4.7.0)
#> GlobalOptions 0.1.3 2025-11-28 [1] CRAN (R 4.6.0)
#> glue 1.8.0 2024-09-30 [2] CRAN (R 4.7.0)
#> golem 0.5.1 2024-08-27 [1] CRAN (R 4.6.0)
#> gridExtra 2.3 2017-09-09 [1] CRAN (R 4.6.0)
#> gtable 0.3.6 2024-10-25 [1] CRAN (R 4.6.0)
#> h5mread 1.3.2 2026-03-08 [1] Bioconductor 3.23 (R 4.7.0)
#> HDF5Array 1.39.0 2025-10-31 [1] Bioconductor 3.23 (R 4.6.0)
#> htmltools 0.5.9 2025-12-04 [2] CRAN (R 4.7.0)
#> htmlwidgets 1.6.4 2023-12-06 [2] CRAN (R 4.7.0)
#> httpuv 1.6.17 2026-03-18 [2] CRAN (R 4.7.0)
#> httr 1.4.8 2026-02-13 [1] CRAN (R 4.7.0)
#> httr2 1.2.2 2025-12-08 [2] CRAN (R 4.7.0)
#> igraph 2.2.2 2026-02-12 [1] CRAN (R 4.7.0)
#> IRanges * 2.45.0 2025-10-31 [1] Bioconductor 3.23 (R 4.6.0)
#> irlba 2.3.7 2026-01-30 [1] CRAN (R 4.6.0)
#> iterators 1.0.14 2022-02-05 [1] CRAN (R 4.6.0)
#> jquerylib 0.1.4 2021-04-26 [2] CRAN (R 4.7.0)
#> jsonlite 2.0.0 2025-03-27 [2] CRAN (R 4.7.0)
#> KEGGREST 1.51.1 2025-11-17 [1] Bioconductor 3.23 (R 4.6.0)
#> knitr 1.51 2025-12-20 [2] CRAN (R 4.7.0)
#> labeling 0.4.3 2023-08-29 [1] CRAN (R 4.6.0)
#> later 1.4.8 2026-03-05 [2] CRAN (R 4.7.0)
#> lattice 0.22-9 2026-02-09 [3] CRAN (R 4.7.0)
#> lazyeval 0.2.2 2019-03-15 [1] CRAN (R 4.6.0)
#> lifecycle 1.0.5 2026-01-08 [2] CRAN (R 4.7.0)
#> limma 3.67.0 2025-10-30 [1] Bioconductor 3.23 (R 4.6.0)
#> locfit 1.5-9.12 2025-03-05 [1] CRAN (R 4.6.0)
#> lubridate 1.9.5 2026-02-04 [1] CRAN (R 4.6.0)
#> magick 2.9.1 2026-02-28 [1] CRAN (R 4.7.0)
#> magrittr 2.0.4 2025-09-12 [2] CRAN (R 4.7.0)
#> Matrix 1.7-5 2026-03-21 [3] CRAN (R 4.7.0)
#> MatrixGenerics * 1.23.0 2025-10-30 [1] Bioconductor 3.23 (R 4.6.0)
#> matrixStats * 1.5.0 2025-01-07 [1] CRAN (R 4.6.0)
#> memoise 2.0.1 2021-11-26 [2] CRAN (R 4.7.0)
#> metapod 1.19.2 2026-02-18 [1] Bioconductor 3.23 (R 4.7.0)
#> mime 0.13 2025-03-17 [2] CRAN (R 4.7.0)
#> otel 0.2.0 2025-08-29 [2] CRAN (R 4.7.0)
#> paletteer 1.7.0 2026-01-08 [1] CRAN (R 4.6.0)
#> pillar 1.11.1 2025-09-17 [2] CRAN (R 4.7.0)
#> pkgconfig 2.0.3 2019-09-22 [2] CRAN (R 4.7.0)
#> pkgdown 2.2.0.9000 2026-03-31 [1] Github (r-lib/pkgdown@a6abe43)
#> plotly 4.12.0 2026-01-24 [1] CRAN (R 4.6.0)
#> plyr 1.8.9 2023-10-02 [1] CRAN (R 4.6.0)
#> png 0.1-9 2026-03-15 [1] CRAN (R 4.7.0)
#> promises 1.5.0 2025-11-01 [2] CRAN (R 4.7.0)
#> purrr 1.2.1 2026-01-09 [2] CRAN (R 4.7.0)
#> R6 2.6.1 2025-02-15 [2] CRAN (R 4.7.0)
#> rafalib 1.0.4 2025-04-08 [1] CRAN (R 4.6.0)
#> ragg 1.5.2 2026-03-23 [2] CRAN (R 4.7.0)
#> rappdirs 0.3.4 2026-01-17 [2] CRAN (R 4.7.0)
#> RColorBrewer 1.1-3 2022-04-03 [1] CRAN (R 4.6.0)
#> Rcpp 1.1.1 2026-01-10 [2] CRAN (R 4.7.0)
#> RCurl 1.98-1.18 2026-03-21 [1] CRAN (R 4.7.0)
#> RefManageR * 1.4.0 2022-09-30 [1] CRAN (R 4.6.0)
#> rematch2 2.1.2 2020-05-01 [1] CRAN (R 4.6.0)
#> reshape2 1.4.5 2025-11-12 [1] CRAN (R 4.6.0)
#> restfulr 0.0.16 2025-06-27 [1] CRAN (R 4.6.0)
#> rhdf5 2.55.16 2026-03-12 [1] Bioconductor 3.23 (R 4.7.0)
#> rhdf5filters 1.23.3 2025-12-07 [1] Bioconductor 3.23 (R 4.6.0)
#> Rhdf5lib 1.33.6 2026-03-16 [1] Bioconductor 3.23 (R 4.7.0)
#> rjson 0.2.23 2024-09-16 [1] CRAN (R 4.6.0)
#> rlang 1.1.7 2026-01-09 [2] CRAN (R 4.7.0)
#> rmarkdown 2.31 2026-03-26 [2] CRAN (R 4.7.0)
#> Rsamtools 2.27.1 2026-03-08 [1] Bioconductor 3.23 (R 4.7.0)
#> RSQLite 2.4.6 2026-02-06 [1] CRAN (R 4.6.0)
#> rsvd 1.0.5 2021-04-16 [1] CRAN (R 4.6.0)
#> rtracklayer 1.71.3 2025-12-14 [1] Bioconductor 3.23 (R 4.6.0)
#> S4Arrays 1.11.1 2025-11-25 [1] Bioconductor 3.23 (R 4.6.0)
#> S4Vectors * 0.49.0 2025-10-30 [1] Bioconductor 3.23 (R 4.6.0)
#> S7 0.2.1 2025-11-14 [1] CRAN (R 4.6.0)
#> sass 0.4.10 2025-04-11 [2] CRAN (R 4.7.0)
#> ScaledMatrix 1.19.0 2025-10-31 [1] Bioconductor 3.23 (R 4.6.0)
#> scales 1.4.0 2025-04-24 [1] CRAN (R 4.6.0)
#> scater 1.39.3 2026-03-20 [1] Bioconductor 3.23 (R 4.7.0)
#> scran 1.39.1 2026-02-25 [1] Bioconductor 3.23 (R 4.7.0)
#> scuttle 1.21.0 2025-11-03 [1] Bioconductor 3.23 (R 4.6.0)
#> Seqinfo * 1.1.0 2025-10-31 [1] Bioconductor 3.23 (R 4.6.0)
#> sessioninfo * 1.2.3 2025-02-05 [2] CRAN (R 4.7.0)
#> shape 1.4.6.1 2024-02-23 [1] CRAN (R 4.6.0)
#> shiny 1.13.0 2026-02-20 [2] CRAN (R 4.7.0)
#> shinyWidgets 0.9.1 2026-03-09 [1] CRAN (R 4.7.0)
#> SingleCellExperiment * 1.33.2 2026-03-24 [1] Bioconductor 3.23 (R 4.7.0)
#> SparseArray 1.11.12 2026-03-30 [1] Bioconductor 3.23 (R 4.7.0)
#> sparseMatrixStats 1.23.0 2025-10-30 [1] Bioconductor 3.23 (R 4.6.0)
#> SpatialExperiment * 1.21.0 2025-11-03 [1] Bioconductor 3.23 (R 4.6.0)
#> spatialLIBD * 1.23.2 2026-01-13 [1] Bioconductor 3.23 (R 4.6.0)
#> statmod 1.5.1 2025-10-09 [1] CRAN (R 4.6.0)
#> stringi 1.8.7 2025-03-27 [2] CRAN (R 4.7.0)
#> stringr 1.6.0 2025-11-04 [2] CRAN (R 4.7.0)
#> SummarizedExperiment * 1.41.1 2026-02-06 [1] Bioconductor 3.23 (R 4.6.0)
#> systemfonts 1.3.2 2026-03-05 [2] CRAN (R 4.7.0)
#> textshaping 1.0.5 2026-03-06 [2] CRAN (R 4.7.0)
#> tibble 3.3.1 2026-01-11 [2] CRAN (R 4.7.0)
#> tidyr 1.3.2 2025-12-19 [1] CRAN (R 4.6.0)
#> tidyselect 1.2.1 2024-03-11 [1] CRAN (R 4.6.0)
#> timechange 0.4.0 2026-01-29 [1] CRAN (R 4.6.0)
#> utf8 1.2.6 2025-06-08 [2] CRAN (R 4.7.0)
#> vctrs 0.7.2 2026-03-21 [2] CRAN (R 4.7.0)
#> vipor 0.4.7 2023-12-18 [1] CRAN (R 4.6.0)
#> viridis 0.6.5 2024-01-29 [1] CRAN (R 4.6.0)
#> viridisLite 0.4.3 2026-02-04 [1] CRAN (R 4.6.0)
#> withr 3.0.2 2024-10-28 [2] CRAN (R 4.7.0)
#> xfun 0.57 2026-03-20 [2] CRAN (R 4.7.0)
#> XML 3.99-0.23 2026-03-20 [1] CRAN (R 4.7.0)
#> xml2 1.5.2 2026-01-17 [2] CRAN (R 4.7.0)
#> xtable 1.8-8 2026-02-22 [2] CRAN (R 4.7.0)
#> XVector 0.51.0 2025-10-31 [1] Bioconductor 3.23 (R 4.6.0)
#> yaml 2.3.12 2025-12-10 [2] CRAN (R 4.7.0)
#>
#> [1] /__w/_temp/Library
#> [2] /usr/local/lib/R/site-library
#> [3] /usr/local/lib/R/library
#> * ── Packages attached to the search path.
#>
#> ──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────Bibliography
This vignette was generated using BiocStyle (Oleś, 2025) with knitr (Xie, 2025) and rmarkdown (Allaire, Xie, Dervieux et al., 2026) running behind the scenes.
Citations made with RefManageR (McLean, 2017).
[1] J. Allaire, Y. Xie, C. Dervieux, et al. rmarkdown: Dynamic Documents for R. R package version 2.31. 2026. URL: https://github.com/rstudio/rmarkdown.
[2] L. A. Huuki-Myers, K. R. Maynard, S. C. Hicks, et al. DeconvoBuddies: a R/Bioconductor package with deconvolution helper functions. https://github.com/LieberInstitute/DeconvoBuddies/DeconvoBuddies - R package version 1.3.2. 2026. DOI: 10.18129/B9.bioc.DeconvoBuddies. URL: http://www.bioconductor.org/packages/DeconvoBuddies.
[3] M. W. McLean. “RefManageR: Import and Manage BibTeX and BibLaTeX References in R”. In: The Journal of Open Source Software (2017). DOI: 10.21105/joss.00338.
[4] A. Oleś. BiocStyle: Standard styles for vignettes and other Bioconductor documents. R package version 2.39.0. 2025. DOI: 10.18129/B9.bioc.BiocStyle. URL: https://bioconductor.org/packages/BiocStyle.
[5] R Core Team. R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing (ROR: <https://ror.org/05qewa988>;). Vienna, Austria, 2026. DOI: 10.32614/R.manuals. URL: https://www.R-project.org/.
[6] H. Wickham. “testthat: Get Started with Testing”. In: The R Journal 3 (2011), pp. 5–10. URL: https://journal.r-project.org/articles/RJ-2011-002/.
[7] H. Wickham, W. Chang, R. Flight, et al. sessioninfo: R Session Information. R package version 1.2.3. 2025. DOI: 10.32614/CRAN.package.sessioninfo. URL: https://CRAN.R-project.org/package=sessioninfo.
[8] Y. Xie. knitr: A General-Purpose Package for Dynamic Report Generation in R. R package version 1.51. 2025. URL: https://yihui.org/knitr/.